arxiv
Google AI Language
2018.10
主要工作
- 提出 BERT (Bidirectional Encoder Representations from Transformers)
- 提出新的 pre-training objective MLM (masked language model)
Transformer 来源于 《Attention is all you need》(论文笔记)
模型
模型架构
Transformer 架构 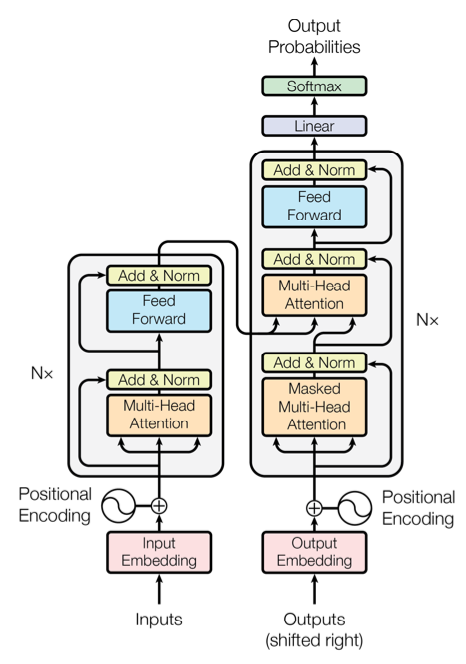
BERT 与 OpenAI GPT, ELMo 的结构对比 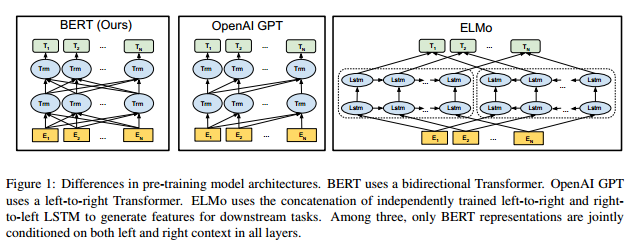
Input Representation
Input Representation 图示 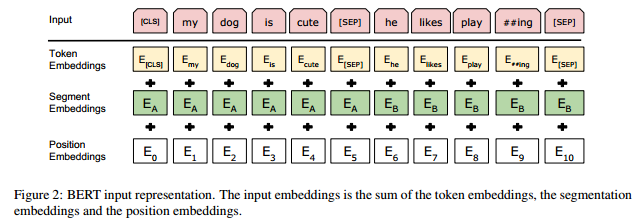
- 这里的 Input Representation 可以表示一个句子或者是一对句子 (例如 QA 对)
- Input Representation 包括 Token, Segment, Position Embeddings
- 使用 WordPiece embeddings (来源论文:Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation)
- 这个 WordPiece Model 介于 Word Model 和 Character Model 之间,就是将 OOV 的词拆开来编码,比如上图中 playing 就被拆成 play 和 ##ing (
##用于表示被切分开的词的接续部分)
- 这个 WordPiece Model 介于 Word Model 和 Character Model 之间,就是将 OOV 的词拆开来编码,比如上图中 playing 就被拆成 play 和 ##ing (
- Position Embeddings 支持的最长序列为 512 个 token
- Token Embeddings 的第一个 token 都是
[CLS],对于分类任务,这一位对应的输出是 aggregate sequence representation,对于非分类任务,这一位无效。 - 输入是一对句子的时候,这些句子将被打包成一句。这里使用两种编码方式分离句子,第一是加入一个特别的 token
[SEP],第二是给句子 A 里的每一个 token 都加上 \(E_A\) (learned sentence A embedding) ,给句子 B 里的每一个 token 都加上 \(E_B\) - 输入是一个句子的时候只使用 \(E_A\)
Pre-training Tasks
Pre-training 是 BERT 最重要的一部分。
BERT 的 pre-training 使用的是两个新的无监督任务。
Task #1: Masked LM
deep bidirectional 模型比传统的 left-to-right 模型和 shallow bidirectional 模型的效果都要好,但是标准 conditional language 模型只能通过这种传统方式训练,因为 deep bidirectional 模型需要每个词都能在多层上下文中间接 “see itself”。为了解决这个问题,文章提出了 masked LM (MLM),即随机屏蔽一些输入中的 token,然后只对这些被屏蔽的 token 进行预测。在本文的实验中,随机屏蔽了 WordPiece tokens 中的 15%。(有点不太懂为什么这样就能训练出 deep bidirectional representation)
- 80% 的情况:替换选中词为
[MASK](my dog is hairy -> my dog is [MASK]) - 10% 的情况:替换选中词为一个随机词 (my dog is hairy -> my dog is apple)
- 10% 的情况:不替换选中词 (my dog is hairy -> my dog is hairy)
Task #2: Next Sentence Prediction
这是针对不能通过语言模型直接学习的下游任务的,例如问答 (QA) 和自然语言推理 (NLI) 之类基于理解句子间关系的任务。
Next sentence prediction 任务可以由任何的 monolingual 语料库构造,就是将语料库中的句子 A 和 B 作为样本,有 50% 的样本里的 B 为 A 在语料库中的下一句,另外 50% 里就是语料库里的一个随机句子。例如:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP] Label = NotNext
Pre-training Procedure
基本基于现有的语言模型 pre-training。
语料库使用 BookCorpus (800M 词) 和 English Wikipedia (2500M 词)。
生成训练输入序列的方法如下:先从语料库中采样两段文本 (本文里称为 “sentences”),第一段接受 A embedding,第二段接受 B embedding。这里对应 next sentence prediction 任务,B 只有 50% 的几率为 A 在语料库中的下一句。采样的时候保证总长度不超过 512 tokens。LM masking 在 WordPiece 序列化之后进行,对应任务 Masked LM。
Fine-tuning Procedure
fine-tuning 的超参在大部分模型中都是和 pre-training 时相同的。dropout 在所有任务中都是 0.1,其他超参根据不同任务有所不同,不过都在以下列举的范围内
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
小数据集相较于大数据集对超参的变化更加敏感。Fine-tuning 一般是很快的,所以在 development set 上穷举所有上述超参,找到效果最好的就行了。
BERT 与 OpenAI GPT 的比较
现有的 pre-training 模式中和 BERT 最接近的就是在大型文本语料库中训练了 left-to-right Transformer 语言模型的 OpenAI GPT。
BERT 和 GPT 最大的区别就是提出了前面说的两个 pre-training tasks (这也是 BERT 效果好的主要来源 ),其他还有几点区别如下:
- GPT 训练使用的语料库是 BooksCorpus,BERT 使用的是 BookCorpus 和 English Wikipedia
- GPT 只在 fine-tuning 的时候使用
[SEP]和[CLS],BERT 在 pre-training 的时候就使用[SEP],[CLS]以及 A/B embeddings - GPT 使用 32000 词的 batch size 训练 1M steps,BERT 使用 128000 词的 batch size 训练 1M steps
- GPT 在所有的 fine-tuning 实验中都使用 5e-5 的学习率,BERT 则为不同任务分别选取表现最好的学习率