arxiv
University of Washington、Microsoft Research
2016.04
这篇文章在 github 上有开源实现(SimpleQA),虽然是 lua 的
主要工作
使用 character-level encoder-decoder 框架解决了 3 个问题,得到了超过 word-level NN 模型的效果。
- 使用 LSTM 对 question 进行 embed,来解决一个 question 有多种表达方式的问题
- 完全使用 character-level 的表征,来解决许多训练的时候没有出现的 KB entity 需要在测试的时候正确预测的问题(对 unseen KB 鲁棒)
- 放弃大规模的输出层,改为由 question embedding 和 KB embedding 之间的语义相似度决定输出,来解决 KB 过于庞大导致预测难度很大的问题
模型
这篇文章也是基于 single-relation question 的。
架构图 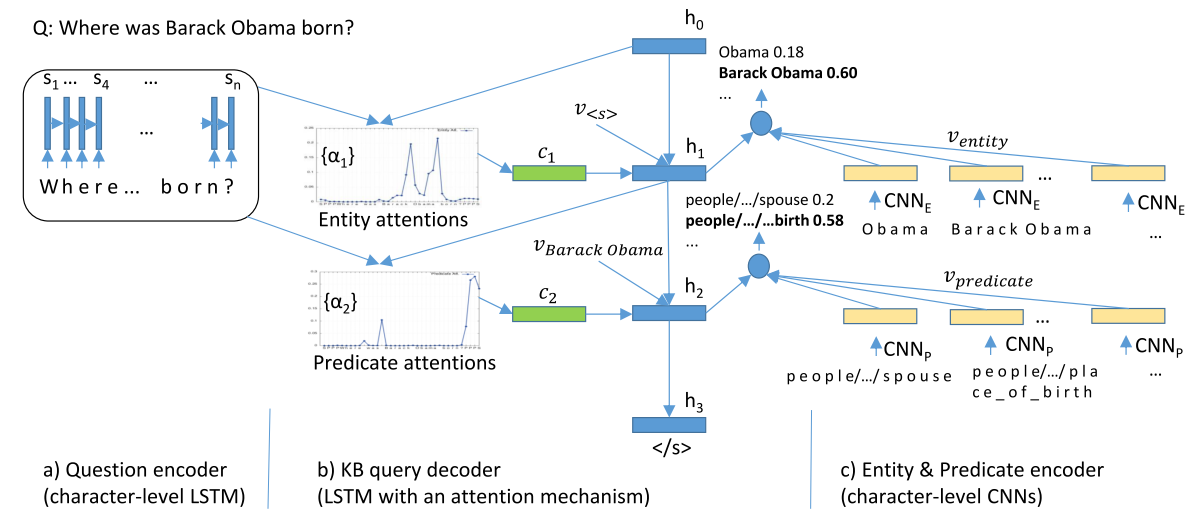
模型有3个组件:
- character-level LSTM-based encoder
用于编码 question
分为两步:- 获得 question 里每个 character 的 one-hot 向量 \(x_1, x_2, ..., x_n\),保留空格、标点和大小写
- 将 \(x_1, x_2, ..., x_n\) 从左至右输入一个两层 gated-feedback LSTM 里,每个 timestep 都输出,获得 question 的 embedding 向量 \(s_1,s_2,...,s_n\)
- character-level CNN-based encoder
用于编码 entity 和 predicate
使用 CNN 而不是 LSTM 是因为 KB 太大了,用 LSTM 会没效率。entity 和 predicate 的 CNN 网络参数不共享是因为 entity 的和 predicate 的形式差别很大。
分为两步:- 获得 entity 或 predicate 的 one-hot 向量 \(x_1, x_2, ..., x_n\)
- 将 \(x_1, x_2, ..., x_n\) 输入一个 temporal CNN(每个 CNN 包含两个卷积层、三个全连接层以及一个 max pooling 层),获得 entity 或 predicate 的 embedding 向量
- \(f(x_1,...,x_n) = tanh(W_3\times max(tanh(W_2\times conv(tanh(W_1\times conv(x_1,...,x_n))))))\)
- 其中 \(f(x_{1...n})\) 是大小为 N 的 embedding 向量
- 使用 attention 机制和相关性衡量函数(relevance function)的 LSTM-based decoder
用于获得 (entity, predicate) 对生成 KB query
分为两个组件:- 基于 attention 的 LSTM-based decoder
- \(c_i= \sum\limits_{j=1}^n\alpha_{ij}s_j\)
- \(\alpha_{ij}=\frac{\exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\)
- \(e_{ij}=v_\alpha^\top tanh(W_\alpha h_{i-1}+U_{\alpha}s_j)\)
- 一对语义相关性衡量函数
- \(P(e_j)=\frac{\exp(\lambda\cos(h_1,e_j))}{\sum_{i=1}^n\exp(\lambda\cos(h_1,e_i))}\)
- \(P(p_k)=\frac{exp(\lambda\cos(h_2,p_k))}{\sum_{i=1}^m\exp(\lambda\cos(h_2,p_i))}\)
- 基于 attention 的 LSTM-based decoder
最后使用 \((e^*,p^*)=argmax_{e_i,p_j}(P(e_i)*P(p_j))\) 获得可能性最大的 (entity, predicate) 对作为输出。
在 SimpleQuestions 上的结果
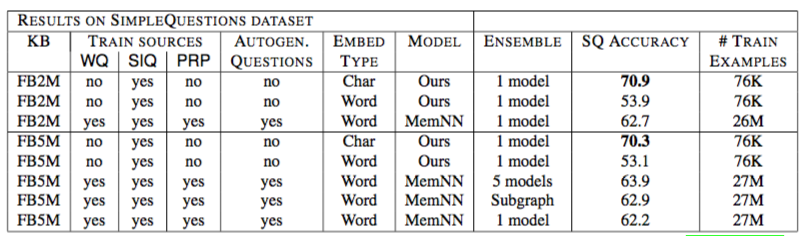 里面的MemNN是《Large-scale Simple Question Answering with Memory Networks》里的,就是原始的强监督 MemNN,不是end-to-end 的。
里面的MemNN是《Large-scale Simple Question Answering with Memory Networks》里的,就是原始的强监督 MemNN,不是end-to-end 的。
WQ 是 WebQuestions, SIQ 是 SimpleQuestions,PRP 是 extracted paraphrases from WikiAnswers
读后感
在 SimpleQuestions 数据集上获得了很不错的结果,网络结构也很清晰,使用 attention 机制解决 KBQA 问题的一个好例子。
特殊的点是用到了 character-level 的 encoder,能够较好的应对 OOV 问题。使用 CNN 来处理 KB 部分也很有意思。
感觉挺有实用参考价值的。