arxiv
Salesforce
2016.03
主要工作
- 改进 Dynamic Memory Networks(DMN),提出 DMN+ 模型
- DMN+ 模型在 VQA 数据集和 bAbI-10k 数据集(无 supporting fact 监督)上都达到了 state-of-the-art
DMN 的结果并不好的情况:
- supporting facts 在训练的时候没有被 marked(无监督?)
- 实用诸如图片等其他形式的数据
模型
DMN+ 相比于 DMN 修改的两部分:
- input representation
- attention 机制与 memory 更新
针对 Text QA 的 input module
在没有 supporting facts 的情况下 DMN 表现不好的原因:
- GRU 只能让句子从上文中获得信息,而不能从下文中获得
- 可能一些 supporting 句子相距太远了,对于 word level GRU 无法获得它们间的关联
模块示例图 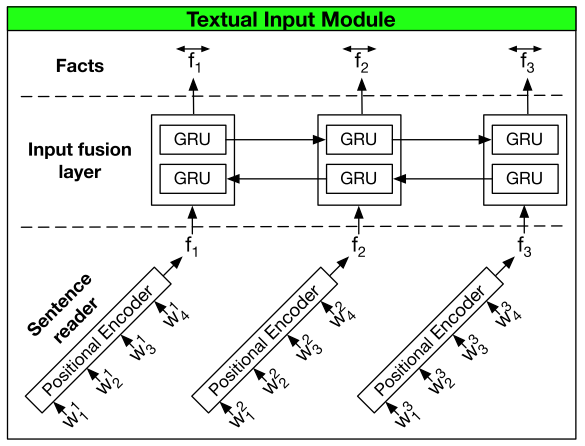
DMN+ 将 DMN 的 input module 由单向 GRU 换成两个组件,Sentence reader 和 Input fusion layer
- Sentence reader
- 负责将输入的词编码为 sentence embedding
- 输入 word tokens \([w_1^i,...,w_{M_i}^i]\),输出 sentence encoding \(f_i\),其中 \(M_i\) 是句子的长度
- 可以使用任意的编码方式,上图里用的 Positional Encoder,用 GRU 或者 LSTM 也可以
- Positional Encoder:
- \(f_i=\sum_M^{j=1}l_j\cdot w_j^i\)
- \(l_{jd}=(1-j/m)-(d/D)(1-2j/M)\)
- 其中,\(d\) 为 embedding index,\(D\) 是 embedding 维度
- Input fusion layer
- 负责获得句子间的关联
- 将 DMN 的单向 GRU 换成双向 GRU(bi-directional GRU)
- Bi-GRU:
- \(\overrightarrow{f_i}=GRU_{fwd}(f_i,\overrightarrow{f_{i-1}})\)
- \(\overleftarrow{f_i}=GRU_{bwd}(f_i,\overleftarrow{f_{i+1}})\)
- \(\overleftrightarrow{f_i}=\overrightarrow{f_i}+\overleftarrow{f_i}\)
针对 VQA 的 input module
模块示例图 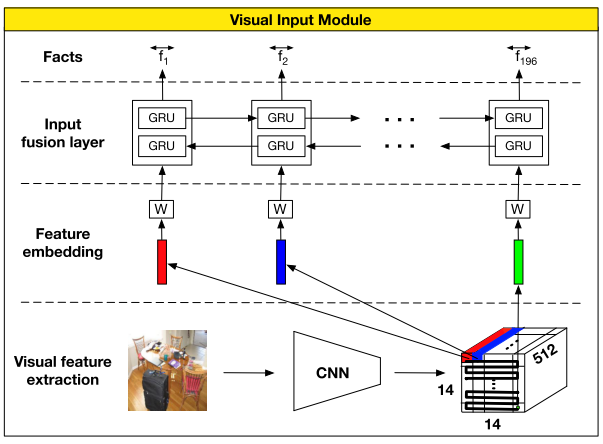
DMN+ 针对 VQA 的 input module 分为 3 个 组件
- Local region feature extraction
- 使用基于 VGG-19 的 CNN
- 首先把输入 rescale 到 448x448,最后的池化层输出维度 \(d=512\times 14\times 14\),也就相当于 196 个 维度为 512 的 local regional 向量
- Visual feature embedding
- 使用 tanh 激活函数的 linear layer
- 用于将 local regional 向量投射到 question 向量使用的文字特征空间
- Input fusion layer
- 和针对 Text QA 的 input module 里的 Input fusion layer 一样
事件记忆模块
模块示例图 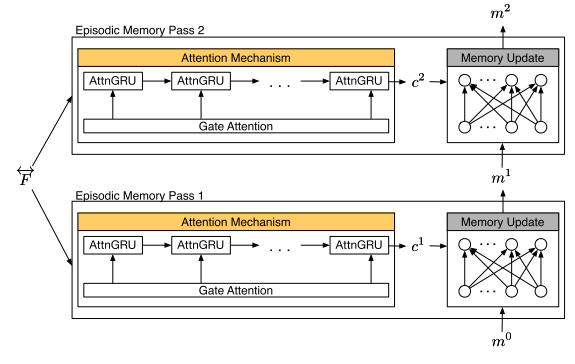
attention gate \(g_i^t\) 的计算如下
\[\begin{align*} &z_i^t=[\overleftrightarrow{f_i}\circ q;\overleftrightarrow{f_i}\circ m^{t-1};|\overleftrightarrow{f_i}-q|;|\overleftrightarrow{f_i}-m^{t-1}|] \\&&&&\\ &Z_i^t=W^{(2)}\tanh (W^{(1)}z_i^t+b^{(1)})+b^{(2)} \\&&&&\\ &g_i^t=Softmax(Z^t)=\frac{\exp(Z_i^t)}{\sum_{k=1}^{M_i}\exp(Z_k^t)} \end{align*}\]
其中, \(\overleftrightarrow{f_i}\) 是第 \(i\) 个 fact,\(m^{t-1}\) 是前一个 memory,\(q\) 是原始问题,\(\circ\) 是 element-wise product,\(|\cdot|\) 是 element-wise 绝对值
 (a) 为传统 GRU 模块,(b) 为基于 attention 的 GRU 模块
(a) 为传统 GRU 模块,(b) 为基于 attention 的 GRU 模块
事件记忆模块主要分为两部分:Attention Mechanism 和 Episode Memory Update
- Attention 机制有两种选择
- Soft Attention
- 直接求加权和,contextual 向量 \(c^t=\sum_{i=1}^Ng_i^t\overleftrightarrow{f_i}\)
- 两个优点:便于计算;如果 softmax 激活是 spiky 的,它可以通过仅选择一个 fact 作为 contextual 向量来保持可微分,接近于 hard attention 函数(?)
- 缺点:求和过程丢失了位置和排序的信息
- 基于 Attention 的 GRU
- 参考上图,把 GRU 单元里的 \(u_i\) 换成了 \(g_i^t\)
- \(h_i=g_i^t\circ\tilde h_i+(1-g_i^t)\circ h_{i-1}\)
- \(g_i^t\) 是一个使用 Softmax 计算的标量,而 \(u_i\) 是一个使用 Sigmoid 计算的 \(n_H\) 维向量
- Soft Attention
- Episode Memory 更新
- 不再像 DMN 里一样用 GRU,而是用了 ReLU layer 来更新 memory
- \(m^t=ReLU(W^t[m^{t-1};c^t;q]+b)\)
if the softmax activation is spiky it can approximate a hard attention function by selecting only a single fact for the contextual vector whilst still being differentiable
读后感
DMN+ 提高了 DMN 的成绩,拓宽了适用范围,感觉实用性非常强,值得深入研究
Attention 和 Memory Networks 的结合使用本身也很有意思