arxiv
2015.06
之前关于词嵌入的理解:学习笔记——词嵌入(Word Embedding)
概述
释义检测(Paraphrase Detection)任务的目标是辨别两个结构和用词有所不同的句子是否拥有相同的含义。释义检测对多个 NLP 任务都很有用,例如 QA,语义分析(Semantic Parsing),文本蕴含关系(Textual Entailment)以及机器翻译。
本文是围绕 PPDB(Paraphrase Database,自动提取了数百万个释义的数据库,数据库中包含了很多具有相同释义的短语/单词对)来进行讨论的。
PPDB 的几个缺点:
- 覆盖率不够高,需要进行释义检测的两个短语必须都在 PPDB 数据库里
- 非参数释义模型(nonparametric paraphrase model),参数(短语对)数量根据数据集大小变化,在实际使用中可能会大到很难处理
- 置信度估计是特征的启发式组合,其质量尚不明确
本文的主要工作:
- 提出新的 PARAGRAM 词向量
- 提出使用 PPDB 来 embed 短语的一些方法
- 提出两个新的数据集,Annotated-PPDB 和 ML-Paraphrase
数据集
Annotated-PPDB
数据集来源于 PPDB 中的短语对子集,根据释义关系强度进行标注。
通过以下步骤建立:
- 过滤短语,只保留 tokens 在词汇表里的短语,删除重复的释义对
- 过滤掉词汇重叠度(word overlap score)大于 0.5 的短语对,例如
<my dad had, my father had> - 根据可释义性的范围选择,10M 中每 1M 采样 5,000 (这个不太确定)
- 根据短语长度选择,从上一步的 5,000 对里选择多种不同长度的短语对 1,500 对,合计 15,000 对
- 精简到 3,000 对,形成 Annotated-PPDB-3K
- 使用 Mechanical Turk 进行标注,1~5 之间,5 代表释义几乎一致,1 代表释义几乎完全不一致甚至矛盾
- 精简到 1,260 对,形成 Annotated-PPDB。这里根据上一步的得分将短语对分成三类,[1, 2.5),[2.5, 3.5],(3.5, 5]
ML-Paraphrase
根据Mitchell和Lapata提出的二元语法相似度任务(bigram similarity task)进行重新标注的数据集。
数据集中包含三类二元语法:adjective-noun (JN),noun-noun (NN),and verb-noun (VN)。
本文发现原有标注中除了功能和定义相似性,还反映了主题相似性,例如<older man, elderly woman>这一对是 JN 中排名最高的。
所以本文的两位作者对数据进行了重新标注,1~5 之间,5 代表释义几乎一致,1 代表释义完全不一致,然后再将评分 1~2 的合并,4~5 的合并,形成了 ML-Paraphrase。
释义模型(Paraphrase Models)
这里提出一个参数释义模型解决之前提到的 PPDB 的第二个缺点。这个模型的目标是将短语映射到低纬的空间中,空间中的余弦相似度代表短语间的释义关系强度。
用的是类似于 Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank 这篇文章中的 RNN。
首先使用成分解析器来获取短语的二进制化解析。对于短语\(p\),通过对其解析的递归计算来获得其向量\(g(p)\),如下 \[g(p)=f(W[g(c_1);g(c_2)]+b)\] 其中 \(c_1\),\(c_2\) 是 \(p\) 的两个子短语,\(f\) 是 element-wise 的 \(\tanh\)。当 \(p\) 没有子词的时候,定义\(g(p)=W_w^{(p)}\),\(W_w\) 就是词嵌入矩阵。
通过短语对来训练词向量时使用目标函数如下 \[ \min_{W_w}\frac{1}{|X|}(\sum_{<x_1,x_2>\in X}\max(0,\delta-W_w^{(x_1)}\cdot W_w^{(x_2)}+W_w^{(x_1)}\cdot W_w^{(t_1)})\\+\max(0,\delta-W_w^{(x_1)}\cdot W_w^{(x_2)}+W_w^{(x_2)}\cdot W_w^{(t_2)}))\\+\lambda_{W_w}||W_{w_{initial}}-W_w||^2 \]
其中 \(t_1\),\(t_2\) 是负样本。
实验
Word Paraphrasing
这个实验用于学习词汇释义,使用来源于 PPDB 的词汇对训练,并使用 SimLex-999(SL999)数据集进行评价。通过这个训练出了 PARAGRAM 词向量,在 SL999 上 ρ 可以达到 0.57。
为了测试 PARAGRAM 词向量,这里把它用在了用于完成情感分析任务的 CNN 里,效果甚至比更高维度的 skip-grams 更好。(但是没有比较 300 维的时候的情况) 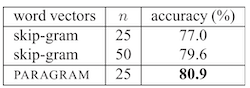
Compositional Paraphrasing
这节包括了各种基于组合短语的释义任务的实验。实验由最简单的二元词组开始到短语结束,每个任务都是从 PPDB 中选取适合的数据进行训练,然后用各种数据集进行验证,包括前面的 Annotated-PPDB 和 ML-Paraphrase。
读后感
因为 Kaggle: Quora Insincere Questions Classification 比赛里有涉及到 paragram_300_sl999这个预训练词嵌入矩阵,所以来看一下这篇论文。
不过文章前面都是用的 25 维的 PARAGRAM 向量和 skip-grams 对比的,最后和 300 维的 GloVe 在自己造的数据集上做了个比较,当然效果是 PARAGRAM 比较好…… 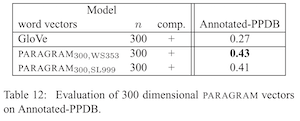
在比赛里的表现感觉还是挺靠谱的,不输 GloVe 和 fasttext 的样子。