现在开始用用英文写一部分报告。
Introduction
Quora Insincere Questions Classification
- Target: A binary classifier to identify insincere questions
- Evaluation: F1 Score
- Environment: Kernels only
Insincere Question:
Questions founded upon false premises, or that intend to make a statement rather than look for helpful answers. for examples:
- Why is it that European food is so terrible? (false premise)
- Why are Quora employees friendly and helpful? (make a statement)
Environment:
- Kernels only, not allow external data
- CPU Kernel <= 6 hours run-time
- GPU Kernel <= 2 hours run-time
- No internet access enabled
- No multiple data sources enabled
- No custom packages
- Submission file must be named “submission.csv”
- Pretrained embeddings:
- GoogleNews-vectors-negative300 (word2vec)
- glove.840B.300d
- paragram_300_sl999
- wiki-news-300d-1M (fasttext)
EDA
train.head(10) 
train["target"].value_counts()  6% of the training data are insincere questions
6% of the training data are insincere questions
train[train.target == 1][0:10] 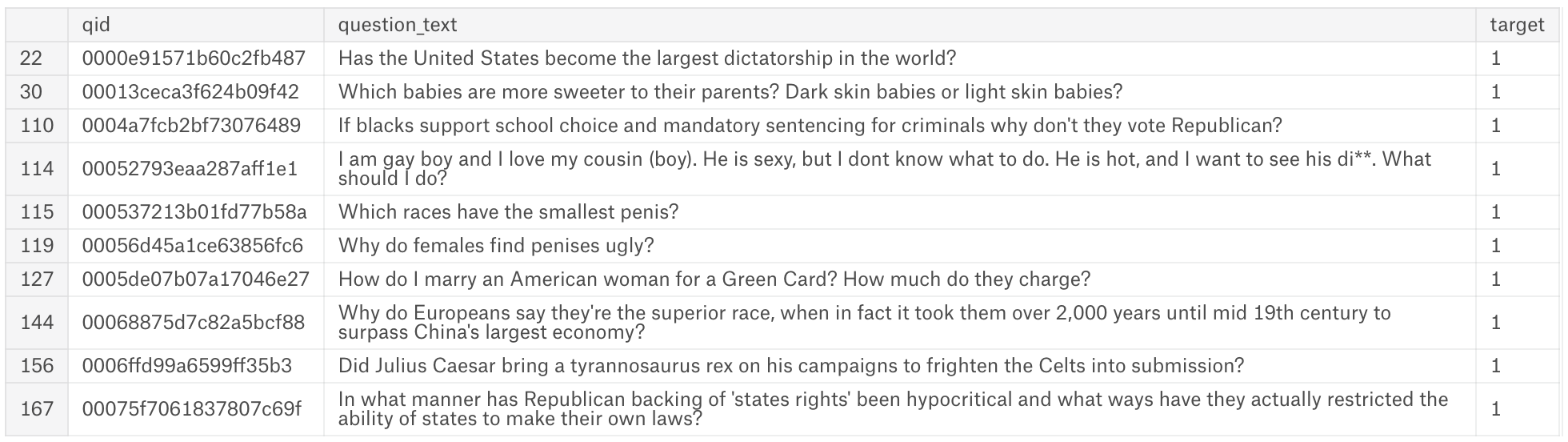 Examples of insincere questions
Examples of insincere questions
train['question_text'].apply(lambda x: len(x.split())).plot(kind='hist') 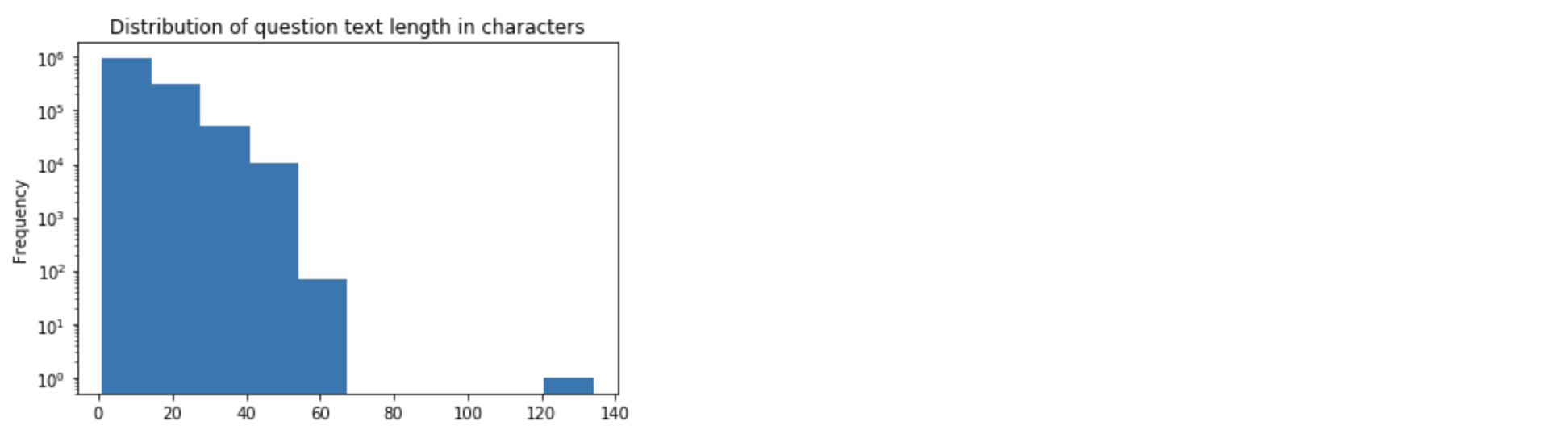 Most questions are 70 words long or shorter
Most questions are 70 words long or shorter
Word Frequency plot of sincere & insincere questions (from: Simple Exploration Notebook - QIQC):
Word 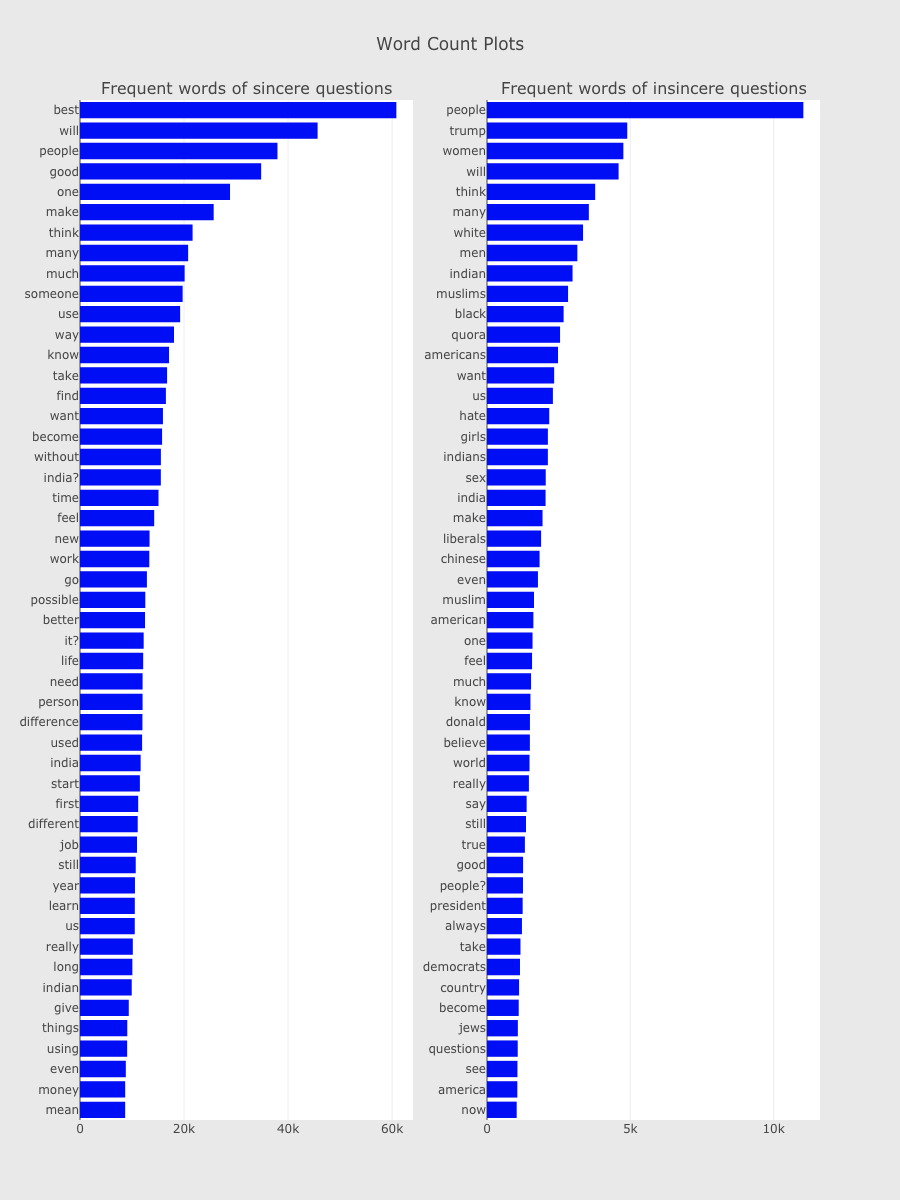
Bigram 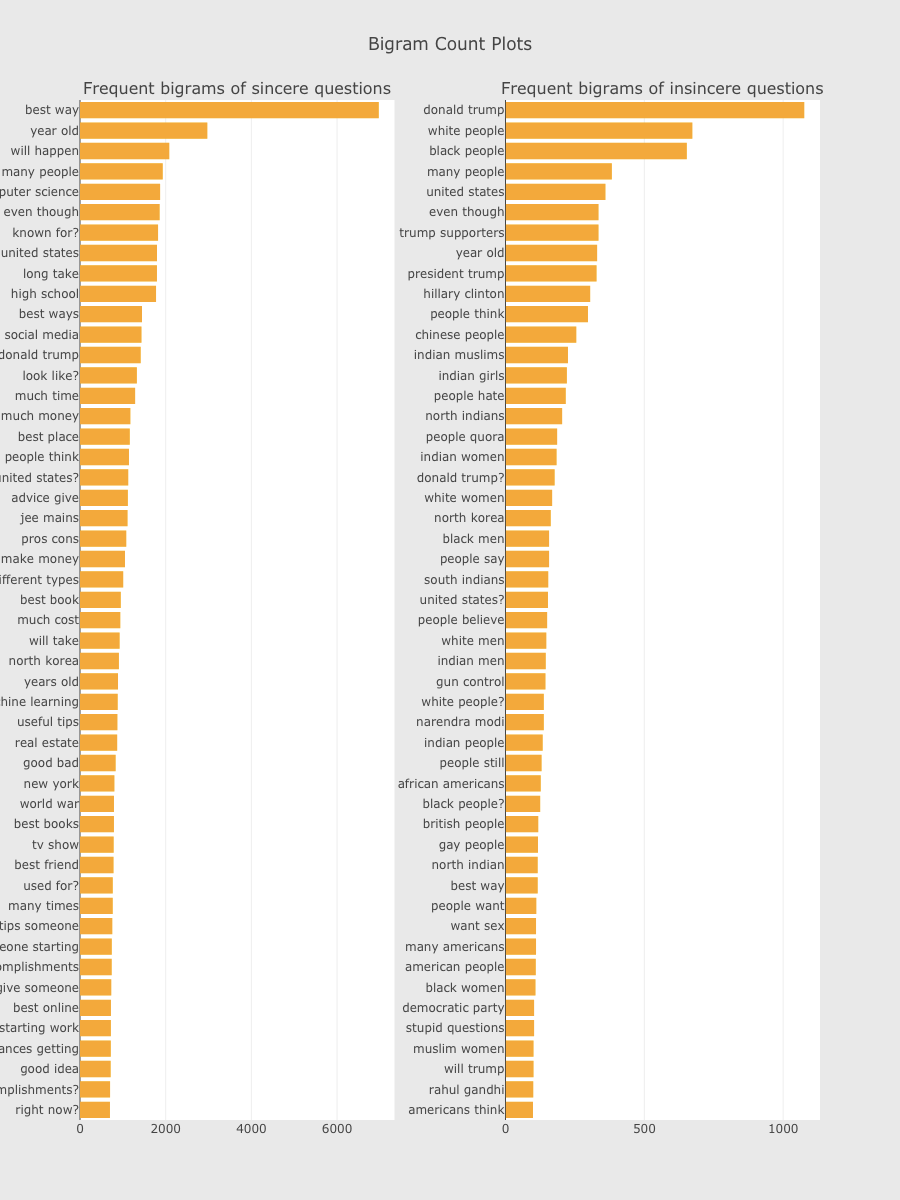
Trigram 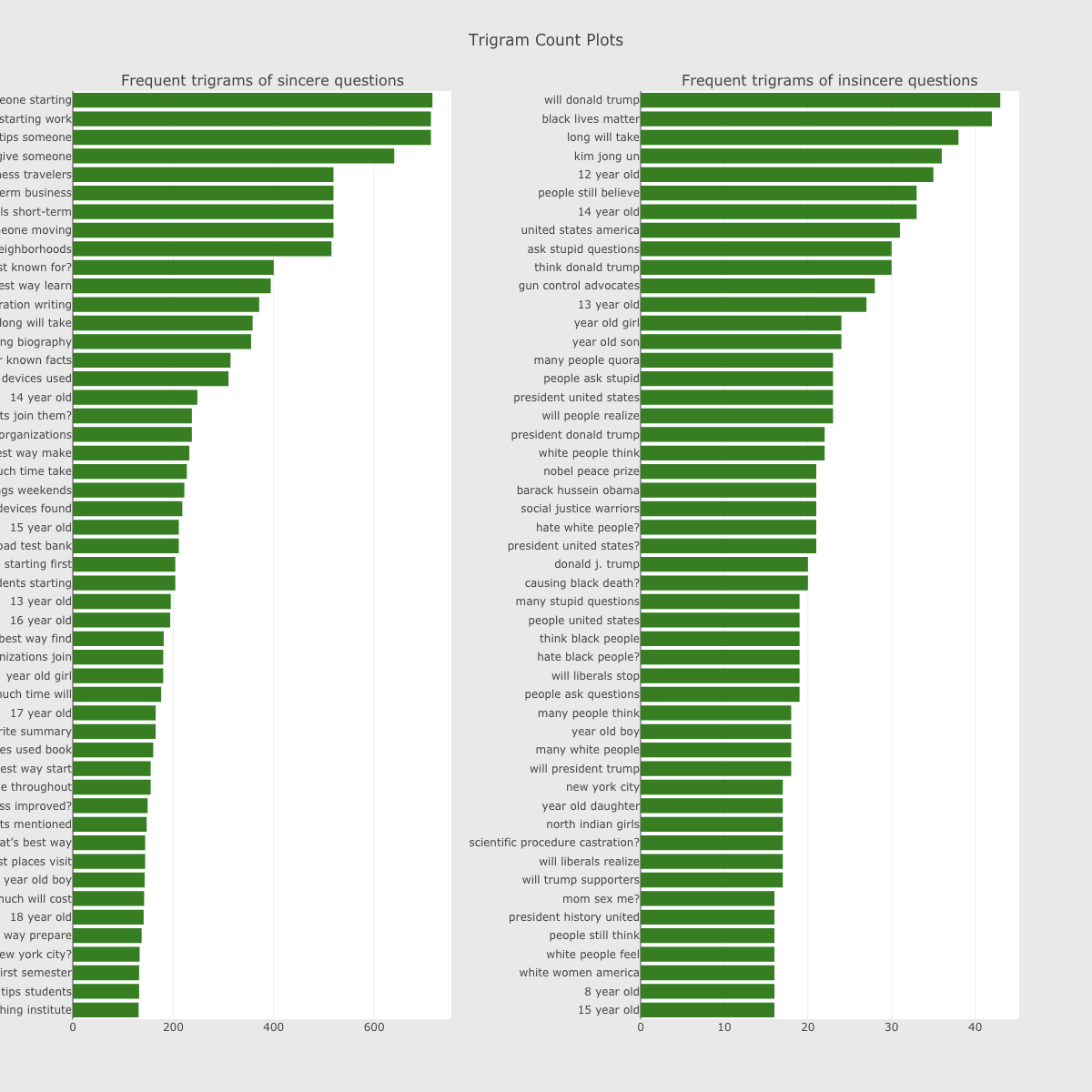
Embeddings
How to use different pretrained embeddings is one of the most important part of this competition.
Some great kernels about embeddings:
- A look at different embeddings.! - A great example of using pretrained embeddings:
- How to: Preprocessing when using embeddings
Reference
- What is an insincere question?
- Simple Exploration Notebook - QIQC
- A look at different embeddings.!
- How to: Preprocessing when using embeddings
Unfinished.