arxiv
Google
2017.06
主要工作
- 提出基于 attention 机制的 Transformer 网络架构
概要
这里还提到了 End-to-end Memory Networks 是基于 recurrent attention 机制的
模型
Transformer 模型架构 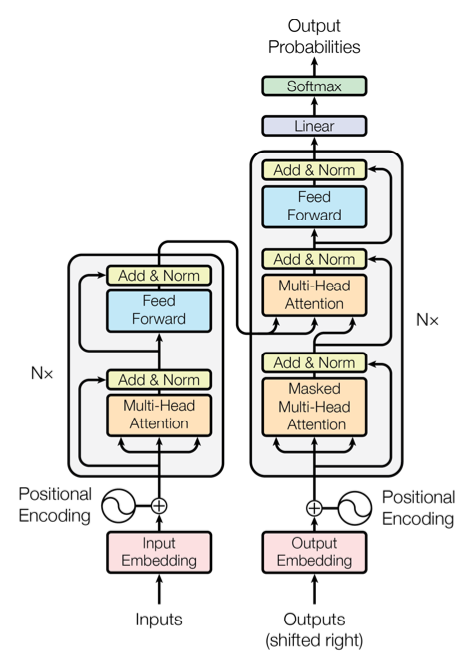
Encoder-Decoder 栈
Encoder
- 由 N=6 个相同的层堆叠起来的,每个层有两个子层
- Multi-Head Self-Attention
- Position-wise Fully Connected Feed-Forward Network
- 每个子层都加上 residual connection 和 layer nomalization,即每个子层的输出都是 \(LayerNorm(x+Sublayer(x))\)
Decoder
- 也是由 N=6 个相同的层堆叠起来的,每个层有三个子层
- Masked Multi-Head Self-Attention
- Multi-Head Self-Attention
- Position-wise Fully Connected Feed-Forward Network
- 也是每个子层都加上 residual connection 和 layer nomalization
Attention
Scaled Dot-product Attention
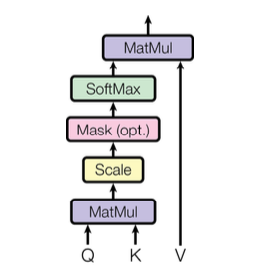 输入包括 queries \(Q\), keys \(K\) 以及 values \(V\) \[Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\] 其中,\(Q\) 和 \(K\) 的维度为 \(d_k\),\(V\) 的维度为 \(d_v\)
输入包括 queries \(Q\), keys \(K\) 以及 values \(V\) \[Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\] 其中,\(Q\) 和 \(K\) 的维度为 \(d_k\),\(V\) 的维度为 \(d_v\)
最常用的两种 attention 函数
- additive attention
使用一个 feed-forward network with a single hidden layer 实现 - dot-product (multiplicative) attention
使用优化好的矩阵乘法实现,所以虽然和 additive attention 理论复杂度差不多,但是实际中效率更高更节省空间
scaled dot-product 就是 dot-product 的结果 \(\times \frac1{\sqrt{d_k}}\),之所以成语这个是因为 \(d_k\) 很大的时候,点乘可能得到很大的结果,将 softmax 函数推到一个梯度很小的区域
Multi-Head Attention
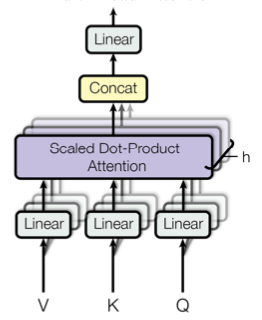 相当于并行通过多个 attention 层再将结果拼接起来,这里这些并行的 attention layers 就叫 heads。 \[MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O\\
where\ head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)
\]
相当于并行通过多个 attention 层再将结果拼接起来,这里这些并行的 attention layers 就叫 heads。 \[MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O\\
where\ head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)
\]
在 Transformer 里应用 Attention
在 Transformer 里 multi-head attention 有 3 种不同的应用方式
- encoder-decoder attention
- 这里的 queries 来自上一个 decoder 层,keys 和 values 来自 encoder 的输出
- 这个 attention 使得 decoder 的每个位置都能与输入序列的每个位置相关联
- encoder
- encoder 里包含一个 self-attention 层,这里的 keys,values 和 queries 都来自 encoder 上一层的输出
- 这个 attention 使得 encoder 的每个位置都能与 encoder 的上一层相关联
- decoder
- 这里的 attention 要使用 scaled dot-product attention 里的 mask
- 这个 attention 使得 decoder 的每个位置都能与decoder 的上一层相关联
Position-wise Feed-Forward Network
网络中 encoder 和 decoder 的每一层都包含一个前馈全连接层(FFN)。 \[FFN(x)=\max(0,xW_1+b_1)W_2+b_2\] FFN 相当于在 ReLU 激活函数前后各做了一次线性变换。
Embeddings 和 Softmax
本文使用 learned embeddings 转换输入和输出 tokens 为 \(d_{models}\) 维的。模型最后使用线性变换 + Softmax 获得概率输出。这 3 个部分共享权重矩阵,在两个 embedding 层里需要把权重乘 \(\sqrt{d_{model}}\)
Positional Encoding
Transformer 通过 PE 来利用序列的顺序信息(因为模型里不含 RNN 和 CNN),在输入和输出的 embedding 层之后都加上了一层 PE。 \(PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}})\) \(PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}})\)
Self-attention 优点
 上表从 3 个角度比较 self-attention,recurrent 和 convolutional 层
上表从 3 个角度比较 self-attention,recurrent 和 convolutional 层
- 每层的计算复杂度
- 可以进行并行计算的数量
- 网络中长期依赖的路径长度
读后感
论文结构很清晰,写的也很简洁,读起来特别舒服。
至于这个抛弃 CNN 和 RNN 的说法是有点怪怪的,不过 Transformer 网络本身感觉挺厉害的,也有应用价值。
Attention 作为研究热点,这篇文章之后还有很多 Multi-Head Attention 的各种应用研究论文。