词汇表征方式——从one-hot到词嵌入
one-hot表征
1个单词对应向量中的1个位置,比如一个有1w个单词的词典中每个词需要由10000x1的向量表示,该单词对应的位置的元素为1,其余位置为0。
例如单词a在词典中的位置为1,则其表征向量为\([1\;0\;0\;0… 0]^T\)
one-hot的缺点:
- 任意两个词之间的乘积都为0,无法表示词汇间的关系,对相关词的泛化能力不强
- 维度太高,计算压力大
- 向量过于稀疏
词嵌入
词嵌入的出现解决了由one-hot进行表征的缺点。
词嵌入是将每个词的one-hot向量映射到更低维的空间,使用低维、稠密、实值的词向量来表示每一个词,每一个维度相当于词的某一个特征。词嵌入使得表示词语之间的相关性成为可能,这种相关性体现在两方面:
- 相似的词语之间的距离相近
- 能够通过多维空间中的距离相似度推理具有类比关系的两组词语
两个词之间的余弦相似度(Cosine similarity):
\[
sim(u,v) = \frac{u^tv}{\|u\|_2\|v\|_2}
\]
词嵌入矩阵
使用词嵌入模型训练词典的目的是获得一个该词典对应的词嵌入矩阵,使用这个词嵌入矩阵与对应的one-hot向量相乘就可以获得该词的词嵌入向量。
在实际工程中,大部分时候我们不自己进行词嵌入模型的训练,而是直接使用训练好的词嵌入矩阵。
符号说明
在具体介绍几种词嵌入方法之前先对一些基本符号进行规定
- \(o_w\)为词\(w\)的one-hot向量
- \(E\)为词嵌入矩阵
- \(e_w\)为词\(w\)的词嵌入向量,\(e_w=E\cdot o_w\)
- \(N\)为词典的大小
Word2vec
Word2vec通过构造监督学习问题来进行训练,而训练的目的不是解决构造出来的监督学习问题,而是获得词嵌入矩阵。
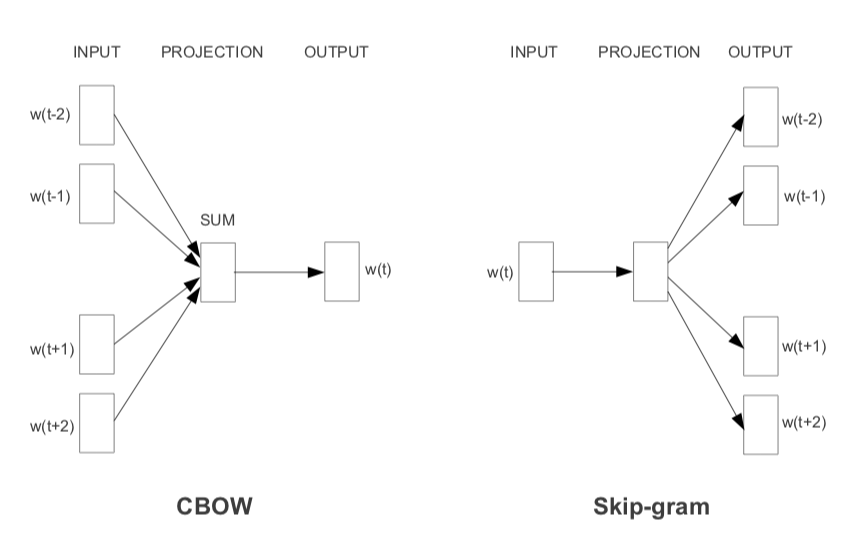
Word2vec提出的模型基于神经网络,三层架构,输入层、隐藏层、输出层。
Word2vec有两种实现模型,一种是skip-gram,一种是CBOW(Continuous Bag of Words)。
- skip-gram通过目标词推测上下文,在大型语料库中表现较好
- CBOW是从原始上下文中推测出目标词,在数据量较小的时候表现较好
 首先定义\(p(o|c)\),表示词\(o\)出现在另一个词\(c\)的上下文语境里的条件概率
首先定义\(p(o|c)\),表示词\(o\)出现在另一个词\(c\)的上下文语境里的条件概率
\[p(o|c)=\frac{exp(\theta_o^Te_c)}{\sum_{n=1}^Nexp(\theta_n^Te_c)}\] 其中,\(\theta\)为softmax层(也就是输出层)的参数矩阵,\(\theta_c\)就是参数矩阵的词\(c\)这一行
CBOW:
CBOW的Loss函数 \[J=\frac1N\sum_{n=1}^N\sum_{-m\le j\le m, j\not=0}log\ p(w_n | w_{n+j})\] 其中,\(j\)是上下文窗口的大小
skim-gram:
skim-gram的Loss函数 \[J=\frac1N\sum_{n=1}^N\sum_{-m\le j\le m, j\not=0}log\ p(w_{n+j} | w_n)\] 其中,\(j\)是上下文窗口的大小
针对softmax层的优化
\({\sum_{n=1}^Nexp(\theta_n^Te_c)}\)这一项相当于需要计算词典中所有词和目标词的余弦相似度,计算量很大,有两种优化方法:
层次Softmax(Hierarchical SoftMax)
通过将原本的softmax层构造成一颗二叉树,将目标概率的计算复杂度从最初的\(O(N)\)降低到了\(O(logN)\)。构造二叉树的方法有很多,不同构造方法会对计算效率和准确率有略微的影响。通常霍夫曼编码树效果还不错,能满足一般需求。负采样(negtive sampling)
负采样不再使用一个具有词汇表大小时间复杂度高的庞大维度的softmax,而是将其转换为词汇表大小个二分类问题,使用逻辑回归解决每个二分类任务。每个的训练样本均是1个正样本,外加k个负样本。
负样本的获得方法(subsampling思想):
\[P(w_c)=\frac{f(w_c)^\alpha}{\sum_{n=1}^Nf(w_n)^\alpha} \] 其中,通常\(\alpha=0.75\),\(f(w_c)\)为词\(c\)在语料库中的词频。
这种获得方法既不用频率分布,也不用均匀分布,而在两者之间进行采样的。这样既不会造成常见词出现频率过高,也不会导致获得的词没有代表性。
负采样的效果比层次softmax的效果要好,目前使用的比较多的也是负采样。
GloVe(global vectors for word representation)
GloVe基于两种方法:
- 基于奇异值分解(SVD)的LSA算法
此处使用的tf-idf主要是全局统计特征。 - Word2vec
基于局部滑动窗口计算,利用了局部的上下文特征。
GloVe方法就是将这两中特征合并到一起的,即使用了语料库的全局统计特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了共现矩阵(Co-occurrence Probabilities Matrix)。
- \(X\)为共现矩阵,其元素为\(X_{i,j}\)。
- \(X_{i,j}\)表示在整个语料库中,单词\(i\)和单词\(j\)共同出现在一个窗口中的次数。
Glove模型的Loss函数: \[J=\sum_{i,j}^{N}{f(X_{i,j})(w_i^Tw_j+b_i+b_j-log(X_{i,j}))^2}\]
其中\(w_i\),\(w_j\)是单词\(i\)和单词\(j\)的词向量,\(b_i\),\(b_j\)是偏差标量,\(f\)是权重函数。
权重函数定义为: \[f(x)=\begin{cases}
(x/x_{max})^{\alpha} &&x < x_{max}\\&&&&\\
1 && x \ge x_{max}
\end{cases}\] 通常,\(x_{max}=100\), \(α=0.75\)。感觉也是subsampling。
Glove没有用到神经网络。
与Word2vec模型相比,GloVe在充分利用了语料库的全局统计信息的同时,也提高了词向量在大语料上的训练速度(一个共现矩阵的遍历要比整个语料库的遍历容易的多)。而与传统的SVD技术相比,SGD的训练也更加简单高效。同时,GloVe得到的词向量更能把握住词与词之间的线性关系。
fastText
fastText 是用于解决文本分类问题的,输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。 fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText预测标签,而 CBOW 模型预测中间词。 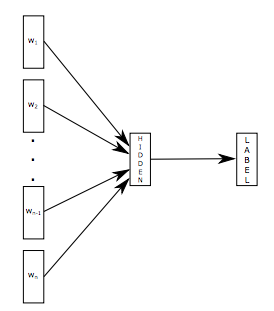 fastText的Loss函数:
fastText的Loss函数:
\[
J=\frac1N\sum_{n=1}^Ny_nlog(f(BAx_n))
\] 其中,\(<x_n,y_n>\)是一条训练样本,\(y_n\)是训练目标,\(x_n\)是词序列的N-gram特征。
fastText的两个技巧:
- Hierarchical SoftMax 与Word2vec中相同,用于加速softmax层的计算
- N-gram features 加入N-gram features提高泛化性能
WordRank
WordRank的资料比较少。下面这部分主要来自论文WordRank: Learning Word Embeddings via Robust Ranking,看的的半懂不懂的。
WordRank是通过Robust Ranking来做的词嵌入。
- \(u_w\)是词\(w\)的词嵌入向量,矩阵\(U := \{u_w\}_{w\in W}\)
- \(v_c\)是上下文的词嵌入向量,矩阵\(V := \{v_c\}_{c\in C}\)
把词\(w\)可能的上下文\(c\)打分排序 \[ rank(w,c)\le \overline{rank}(w,c)=\sum_{c'\in C \setminus \{c\}}\ell(\langle u_w,v_c-v_c'\rangle) \] Loss函数 \[ J = \sum_{w\in W}\sum_{c\in \Omega_w}r_{w,c}\cdot\rho(\frac {\overline{rank}(w,c) + \beta}{\alpha}) \] 其中, \[ r_{w,c}=\begin{cases} (X_{w,c}/x_{max})^\epsilon & if\ X_{w,c} \le x_{max} \\&&&&\\ 1 & otherwise \end{cases} \] 通常,\(x_{max} = 100\),\(\epsilon = 0.75\),这个\(r_{w,c}\)和GloVe里的权重是一个意思。
几种方法的比较
FastText在语法类比任务中效果最好,GloVe在多义词方面表现最好,那么wordRank在语义类比任务中效果最好。
其原因在于,FastText引入词的形态学信息,而WordRank则是把寻找最相似词形式化为一个排序问题。即,给定词w, WordRank输出一个序列化列表,将和词w共同出现最多的词排在列表前面。
- 在语义类比中,三种模型在低频词语上表现相对较差,在高频词语上表现效果较好;
- 在语法类比中,FastText优于Word2Vec和WordRank 。FastText模型在低频词语上表现的相当好,但是当词频升高时,准确率迅速降低,而WordRank和Word2Vec在很少出现和很频繁出现的词语上准确率较低;
- FastText在综合类比中表现更好,整体类比结果与语法类比的结果比较相似,因为语法类比任务的数量远远多于语义类比,所以在综合结果中语法类比任务的结果占有更大的权重。