arxiv
Facebook AI
2016.06
主要工作
- 提出 Key-Value Memory Networks(KV-MemNNs)架构
- 构建 QA 数据集 WikiMovies
模型
架构图 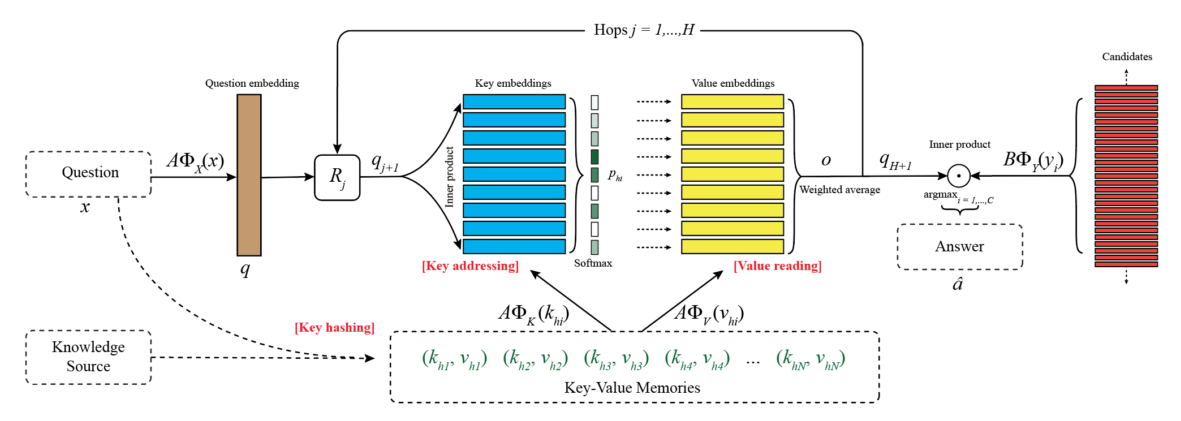 模型架构基于 MemN2N,不同的地方在于把 memory slots 定义成向量对 \((k_1,v_1),...,(k_M,v_M)\)
模型架构基于 MemN2N,不同的地方在于把 memory slots 定义成向量对 \((k_1,v_1),...,(k_M,v_M)\)
模型流程
定位读取 memory 分为 3 步
- Key Hashing:根据问题 \(x\) 预先选择出 N 个memory 对 \((k_{h_1},v_{h_1}),...,(k_{h_N},v_{h_N})\),要求这些 key 至少有一个词和问题里的相同(要求是词频小于 1000 的词,为了排除停用词)
- Key Addressing:通过比较问题和每个 key 计算 memory 对和问题的相关可能性(relevance probability):\(p_{h_i}=Softmax(A\Phi_X(x)\cdot A\Phi_K(k_{h_i}))\),其中,\(\Phi\) 是维度为 D 的 feature maps,\(A\) 是 \(d\times D\) 矩阵
- Value Reading:使用加权和读取 value,返回 \(o=\sum\limits_ip_{h_i}A\Phi_V(v_{h_i})\)
上面的步骤重复进行 H hops
- controller 神经网络使用 \(q=A\Phi_X(x)\) 作为 query
- 在得到 hop 1 的 \(o\) 后,hop 2 的 query 更新为 \(q_2=R_1(q+o)\),\(R\) 是 \(d\times d\) 矩阵。
- hop \(j\) 有 \(R_j\),\(q_{j+1}=R_j(q+o)\),\(p_{h_i}=Softmax(q_{j+1}^\top A\Phi_K(k_{h_i}))\)
- 在 H hop 之后,输出预测结果 \(\hat a=\arg\max_{i=1,...,C}Softmax(q_{H+1}^\top B\Phi_Y(y_i))\),\(y_i\) 是可能的候选输出
矩阵 \(A\),\(B\),\(R_1,...,R_H\) 是训练中需要学习的参数
Key-Value 实现方式
- KB Triple
KB,针对 triples(subject, relation, object),key 是 subject 和 relation,value 是 object。然后需要将 subject 和 object 交换,relation 取反再存一次(KB 大小翻倍) - Sentence Level
document,每个 memory slot 编码一个句子的情况,key 和 value 都是用 bag-of-words 的形式编码的整个句子(和标准 MemNN 里一样) - Window Level
document,分割成 W 个词的窗口(中心词是实体),key 是用 bag-of-words 编码后的整个窗口,value 是中心词 - Window + Center Encoding
document,和 Window Level 的区别就是使用不同 feature 对中心词和窗口中除了中心词以外的词进行编码 - Window + Title
document,key 还是上面两条提到的窗口,value 是 document 的 title,另外也保留 Window Level 里的所有 memory 对
WikiMovies
WikiMovies 数据形式 
知识形式
包括 3 种知识形式
- Doc:原始 Wikipedia document
- KB:传统 KB,根据 Open Movie Database(OMDb)和 MovieLens 创建
- IE:information extraction 表示的,和 2 类似的 KB
读后感
面对 KB 存在的问题,选择探究基于文档的 QA,感觉比较有工程价值。
但是毕竟没有基于开放域
另外也算是完善 MemN2N 的实现了