arxiv
Facebook AI
2015.06
主要工作
- 创造了数据集 SimpleQuestions,用于评估 现有系统的覆盖率 和 不同数据源使用多任务学习进行联合训练的可行性(迁移学习)
- 提出了基于 Memory Networks(MemNNs)框架的 embedding-based QA 系统
- study the coverage of existing systems and the possibility to train jointly on different data sources via multitasking
- present an embedding-based QA system developed under the framework of Memory Networks (MemNNs)
研究现状:由于训练集通常只能包含一小部分问题,所以训练大规模的QA系统很难。
相关KB:Freebase、Reverb
Simple QA
三元组(triples): (subject, relationship, object)
Simple QA:推理过程只设计到单个 facts
KB
KB 数据量 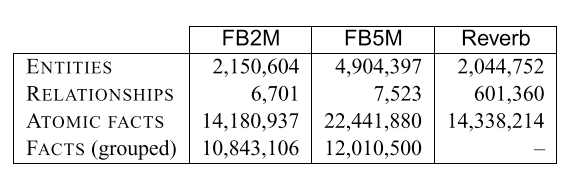
Freebase
取了 Freebase 的两个选录,FB2M 和 FB5M
- FB2M: 2M entities 和 5k relationships(文章里说5k,图里是6.7k……)
- FB5M: 5M entities 和 7.5k relationships
Reverb
用于迁移学习的 KB。
选择 Reverb 是因为它和 Freebase 很不同。 Freebase 是 Curated KB,Reverb 是 Extracted KB。
SimpleQuestions
包含 108442 个 questions,答案来自 FB2M。
收集分为两个阶段:
- 选出来自 FB2M 用于产生 questions 的一系列 facts ,其中,删除了所有包含未知 relationship 的 facts,也删除了所有答案数量会超过阈值(10)的 facts
- 把选出来的 facts 给标注员产生对应 questions
MemNN模型
I、G、O、R模块
- Input module (I):对 Freebase facts、questions、Reverb facts 进行预处理,将其转化为向量表示。
- 预处理Freebase:把 Freebase 的数据处理成适配 QA 任务的形式
- grouping:把具有相同 subject 和 relation 的 fact 聚合成一个新的 fact,应对多答案问题。例如 \((s, r, o_1)\) 和 \((s, r, o_2)\) 合成为 \((s, r, \{o_1, o_2\})\)
- 删除中间节点:把多个 fact 表示的复杂关系简化为1个 fact,这样减少推理过程,让 simple QA 可以解决更多问题。例如 \((s, r_1, o_1)\) 和 \((o_1, r_2, o_2)\) 合成为 \((s, r_2, o_2)\)
- 预处理Freebase facts:向量化三元组,使用 bag-of-symbol 表征, 得到 \(N_S\) 维(entities 和 relationships 数量之和)的向量 \(f(y)\)。\((s, r, \{o_1, o_2, ..., o_k\})\) 这类聚合三元组里每个实体的代表维度的值为 \(1/k\) 而不是 \(1\)
- 预处理questions:向量化问题,使用 bag-of-ngrams 表征,得到 \(N_V\) 维(字典大小)的向量 \(g(q)\)
- 预处理Reverb facts:向量化三元组,使用 bag-of-symbol 表征 s 和 o,使用 bag-of-words 表征 r,得到 \(N_S+N_V\) 维的向量 \(h(y)\)
- 预处理Freebase:把 Freebase 的数据处理成适配 QA 任务的形式
- Generalization module (G):用于向 memory 中添加新元素,就是将 Reverb facts 和 Freebase-based memory structure 建立连接(用于迁移学习)
- Output module (O):根据输入,找到对应的 supporting fact
- 生成候选facts:通过问题的 n-grams of words 在 Freebase 里找到少量相关匹配实体
- Scoring:使用 embedding 模型对候选 facts 进行评分,最高得分的为 supporting fact
- question \(q\) 和 Freebase fact \(y\) 之间相似度的计算公式:\(S_{QA}(q,y)=cos(W_Vg(q),W_Sf(y))\),\(W_V\) 和 \(W_S\) 是 embedding 矩阵,维度分别为 \(d\times N_V\) 和 \(d\times N_S\)
- question \(q\) 和 Reverb fact \(y\) 之间相似度的计算公式:\(S_{RVB}(q,y)=cos(W_Vg(q),W_{VS}h(y))\),\(W_{VS}\) 也是 embedding 矩阵,维度为 \(d\times (N_V+N_S)\)
- \(d\) 是超参,embedding 矩阵 \(W_V\) 和 \(W_S\) 是要通过训练学习的参数
- Response module (R):直接返回 output module 选择的 supporting fact 集合
实验步骤
- 存储Freebase:用 (I) 预处理 Freebase 并存进 memory 里
- 训练:训练 MemNN 模型回答问题,需要用到 (I)、(O)、(R)
- 连接Reverb:把 Reverb 数据也存入 memory 里,用于测试 MemNN 的泛化能力,需要用到 (I) 进行预处理,用到 (G) 将 Reverb facts 和memory里已经存在的 facts 连接
Multitask
使用多任务学习方式训练 (O) 里的 scoring 部分。
训练集:
- QA dataset:SimpleQuestions、WebQuestions
- automatic questions:由 FB2M 或 FB5M 自动生成
- paraphrases dataset:Wikianswers
多任务训练目标:
- 对 QA dataset:supporting fact 在 embedding 空间里与 question 最相近(和 non-supporting fact 相比)
- loss function:\(l_{QA}(q,y,y')=[\gamma-S_{QA}(q,y)+S_{QA}(q,y')]_+\),其中 \(\gamma\) 是超参
- 对paraphrases dataset:question 和它的某一个 paraphrases 最接近(和其他 question 相比)
- loss function:\(l_{QQ}(q,q',q'')=[\gamma-S_{QQ}(q,q')+S_{QQ}(q,q'')]_+\)
针对 WebQuestions 的监督:因为 WebQuestions 只提供文字答案,不提供 supporting fact,所以在训练的时候要用 (O) 中的候选 facts 生成的方法找到相应 fact
生成负样例:根据 randomized policy 在训练中生成负样例
读后感
这篇文章最大的贡献是给出了 SimpleQuestions。
迁移学习的思路应该多研究一下。
另外就是数据预处理的思路值得借鉴。