AAAI
Institute of Automation, Chinese Academy of Sciences, China
2015.01
keras 实现:Github
主要工作
- 提出 recurrent convolutional neural networks(RCNN),不需要像传统文本分类那样人工进行特征工程
模型
RCNN架构 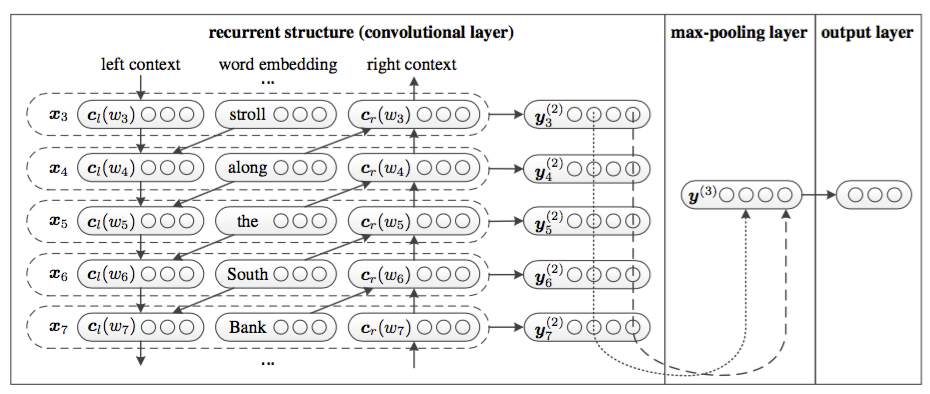
Word Representation Learning
使用一个双向 RNN 网络,结合 word 及其 context 来进行 word representation。
这个双向 RNN 部分输入是 words 序列 \(w_1,w_2,...,w_n\),输出是 \(x_1,x_2,....,x_n\)。\(x_i\) 中包括 \(c_l(w_i)\)、\(c_r(w_i)\) 以及 \(e(w_i)\)。其中 \(e(w_i)\) 是 \(w_i\) 的 word embedding。
\[ c_l(w_i)=f(W^{(l)}c_l(w_{i-1})+W^{(sl)}e(w_{i-1}))\\ c_r(w_i)=f(W^{(r)}c_r(w_{i-1})+W^{(sr)}e(w_{i-1}))\\ x_i=[c_l(w_i);e(w_i);c_r(w_i)] \]
然后再由 \(x_i\) 进行一个线性变换在通过一个 tanh 激活函数获得 \(y_i^{(2)}\)
\[y_i^{(2)}=tanh(W^{(2)}x_i+b^{(2)})\]
\(y_i^{(2)}\) 是一个潜在语义向量(latent semantic vector),用于决定最能表示 text 的因子
Text Representation Learning
CNN 部分用来进行 text representation,前面提到的那些 RNN 部分就是卷积层的本质
每个 word 的潜在语义向量都计算好之后输入到一个 max pooling 层里得到 \(y^{(3)}\) \[y^{(3)}=\max\limits_{i=1}^ny_i^{(2)}\] 这里之所以用 max pooling 而不用 average pooling 是因为一段 text 里只有小部分 word 对理解文档意思有帮助。
最后输出层进行线性变化和 softmax: \[ y^{(4)}=W^{(4)}y^{(3)}+b^{(4)}\\ p_i=\frac{exp(y_i^{(4)})}{\sum_{k=1}^n exp(y_k^{(4)})} \]
实现
Github 上的实现,模型部分如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26document = Input(shape = (None, ), dtype = "int32")
left_context = Input(shape = (None, ), dtype = "int32")
right_context = Input(shape = (None, ), dtype = "int32")
embedder = Embedding(MAX_TOKENS + 1, embedding_dim, weights = [embeddings], trainable = False)
doc_embedding = embedder(document)
l_embedding = embedder(left_context)
r_embedding = embedder(right_context)
# I use LSTM RNNs instead of vanilla RNNs as described in the paper.
forward = LSTM(hidden_dim_1, return_sequences = True)(l_embedding) # See equation (1).
backward = LSTM(hidden_dim_1, return_sequences = True, go_backwards = True)(r_embedding) # See equation (2).
# Keras returns the output sequences in reverse order.
backward = Lambda(lambda x: backend.reverse(x, axes = 1))(backward)
together = concatenate([forward, doc_embedding, backward], axis = 2) # See equation (3).
semantic = Conv1D(hidden_dim_2, kernel_size = 1, activation = "tanh")(together) # See equation (4).
# Keras provides its own max-pooling layers, but they cannot handle variable length input
# (as far as I can tell). As a result, I define my own max-pooling layer here.
pool_rnn = Lambda(lambda x: backend.max(x, axis = 1), output_shape = (hidden_dim_2, ))(semantic) # See equation (5).
output = Dense(NUM_CLASSES, input_dim = hidden_dim_2, activation = "softmax")(pool_rnn) # See equations (6) and (7).
model = Model(inputs = [document, left_context, right_context], outputs = output)
model.compile(optimizer = "adadelta", loss = "categorical_crossentropy", metrics = ["accuracy"])
根据这段源码, \[y_i^{(2)}=tanh(W^{(2)}x_i+b^{(2)})\] 这个公式可以用
semantic = Conv1D(hidden_dim_2, kernel_size = 1, activation = "tanh")(together)
来实现。
读后感
主要是在 Toxic 比赛中看到了有人用这种网络,而且是效果最好的一种,所以看了这篇文章。
但文章里对 CNN 的描述我还有点没看懂,后来看了源码才理解 \(y_i^{(2)}\) 也算是一个移动窗口,好像是卷积的那么个意思……