翻译一篇 Blog:Twitter Sentiment Analysis Using Combined LSTM-CNN Models
实现源码:github
Paper(好像没发表)
其实 LSTM-CNN 的模型结构我在论文《Recurrent Convolutional Neural Networks for Text Classification》(笔记)里已经看到过了,但是论文的 CNN 部分把我搞得有点晕,而这篇 Blog 的描述方式的更浅显,另外还专门比对了一下 LSTM 和 CNN 在模型中的放置顺序问题,结果非常有趣并且很合理。另外就是 Kaggle 的 Toxic 比赛里专门有人提到这篇 Blog,所以我翻译了一下,方便回看。
以下为翻译部分
为什么选择 CNNs 和 LSTMs
CNNs
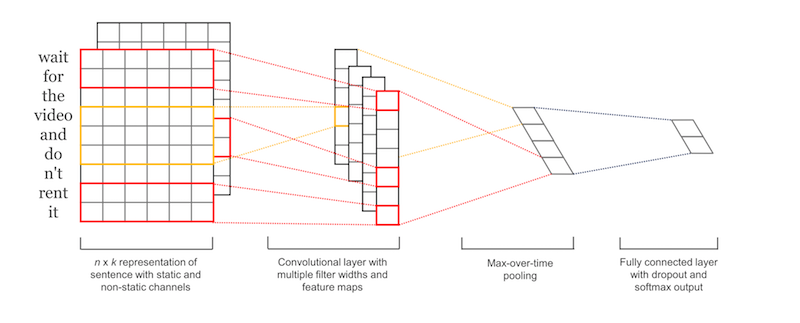
CNN 最初的出现是为了解决图像相关任务的,它能无视位置因素捕获特定特征。
举个具体的例子,假设我们用 CNN 来区分汽车和狗的图片,由于 CNN 能够做到无视位置捕捉特征,因此 CNN 学习到汽车有轮子后,无论在图片的哪个位置看到轮子,CNN 都能够激活(轮子)这个特征。
在我们这个任务中,CNN 能够捕捉到负面短语例如 don’t like,无论这个短语在推文的哪个位置。
- I don’t like watching those types of films
- That’s the one thing I really don’t like.
- I saw the movie, and I don’t like how it ended.
LSTMs
LSTM 是一种具有记忆功能的网络,它能够记忆之前输入的内容并依据这些内容进行输出。LSTM 更适用于输入为文本数据的情况,因为一个句子中的每个单词的意义都与其周围的单词有关(前面或后面的单词)。
在我们这个任务中,LSTM 可以捕捉到推文中变化的情绪。比如,类似 At first I loved it, but then I ended up hating it. 这样的句子,它具有相互矛盾的情感,这通常会导致一般的前馈网络(Feed-Forward network)混乱。但是 LSTM 可以做到让句子末尾的意思比句子开头的意思更为重要。 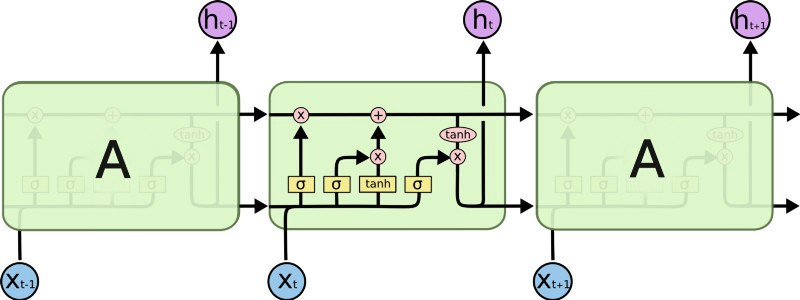
Twitter 数据
本实验中使用的 Twitter 数据混合使用了两个数据集:
- The University of Michigan Kaggle competition dataset.
- The Neik Sanders Twitter Sentiment Analysis corpus.
这两个数据集共包含 1,578,627 条标注好的推文。
CNN-LSTM 模型
首先我尝试了 CNN-LSTM 模型。首先将 word embedding 输入到初始的卷积层里,然后将其输出通过 max pooling 层获得维度较少的输出并输入到 LSTM 层中。
这个模型背后的想法是先用卷积层获得局部特征,然后使用 LSTM 层通过局部特征的顺序来获得输入文本的顺序。实际上,这个模型不如我们下面要提出的 LSTM-CNN 模型强大。 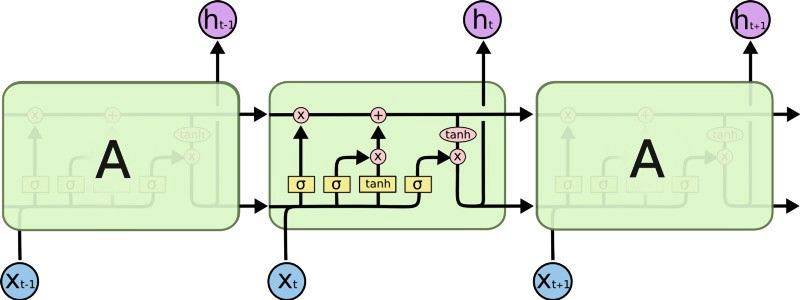
LSTM-CNN 模型
LSTM-CNN 模型首先将 word embedding 输入到一个 LSTM 层里,这里相当于是将原始输入进行了一个编码,它的输出将不光包含当前 token 的信息,也将包含所有前面 token 的信息。然后将 LSTM 层的输出输入到卷积层里,再通过 max pooling 层、全连接层最后输出。 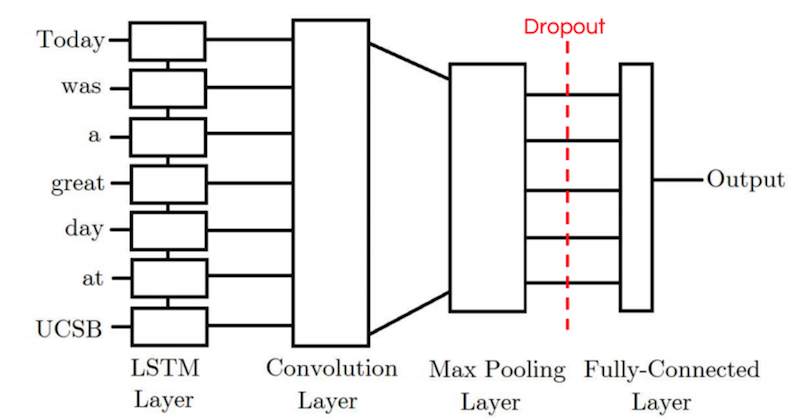
结果
实验取 10,000 条推文作为训练集,2,500 条推文作为测试集。训练和测试集中的正负样本数量一致。我们重复测试 5 次取平均值作为结果。
调参后的参数如下图: 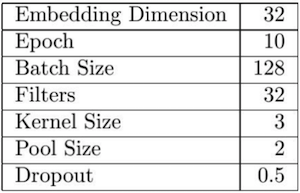
最终的结果如下图: 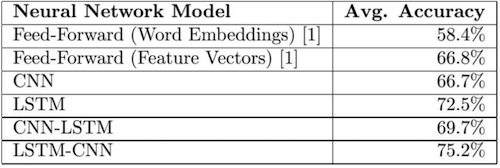
CNN-LSTM 模型的准确率比 CNN 模型高 3%,但比 LSTM 模型低 3.2%。同时,LSTM-CNN 模型比 CNN 模型的性能好 8.5%,比 LSTM 模型好 2.7%。
这些结果似乎表明我们一开始的想法是正确的,通过结合使用 CNN 和 LSTM,我们能够利用 CNN 识别局部特征的能力,以及LSTM 识别文本顺序的能力。只是,模型中卷积层和 LSTM 层的顺序至关重要。
我们相信模型之间 5.5% 的准确率差不是巧合。看起来 CNN-LSTM 的初始卷积层丢失了一些文本的顺序/序列信息。因此,如果卷积层的顺序没有给我们提供任何信息,那么 LSTM 层将只起到全连接层的作用。这种模式似乎无法让 LSTM 层起到它该有的作用,事实上,它甚至比常规的 LSTM 模型表现更差。
另一方面,LSTM-CNN 模型似乎是最好的,因为它的初始 LSTM 层看起来像一个编码器,因此对于输入中的每个 token 都有一个输出 token,其中不仅包含原始 token 的信息,而且还包含之前所有 token 的信息。之后,卷积层将使用具有比原始输入更丰富的信息的数据来寻找局部特征,从而达到更高的准确率。
进一步观察
实验过程中做的一些观察(论文中有更详细的解释):
学习率
CNN 和 CNN-LSTM 模型相比于 LSTM 和 LSTM-CNN 模型,需要更多个 epochs 来进行训练,更晚过拟合。 
Drop 率
这个结果不令人意外,在 CNN-LSTM 或 LSTM-CNN 模型的卷积层之后加入 Dropout 层很重要。 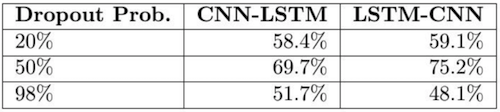
预训练 word embeddings
我尝试使用了预训练 word embeddings,而不是让系统从我们的数据中学习 word embeddings。令人惊讶的是,使用这些预先训练好的GloVe word embeddings 导致了更差的准确率。我想这可能是由于推文中包含很多拼写错误,表情符号,缩写以及其他构建 GloVe word embeddings 时没考虑到的 Twitter 特有的文字。 
总结&今后的研究方向
今后的研究中,我可能会尝试使用其他类型的 LSTM(例如 Bi-LSTM)看看这对系统准确率的影响。找找解决推文中的拼写错误和其他不规则词汇的办法也是一个很有趣的方向。我想构建 Twitter 特有的 word embedding 会是一个好办法。最后,找到利用 Twitter 特有的一些功能(转发,喜爱等)进行训练的方法也是一个有趣的方向。