概述
集成学习(Ensemble learning)通过组合几种模型(学习器)来完成学习任务,也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
集成学习中要求个体学习器的准确率至少不差于弱学习器(弱学习器指泛化性能略优于随机猜测的学习器),并且个体学习器之间要有多样性(diversity)。即 好而不同。
根据个体学习器分类
- 同质集成(homogeneous)集成中只包含同种类型的个体学习器,例如’决策树集成’、‘神经网络集成’。这里的个体学习器又叫基学习器(base learner)
- 异质集成(heterogenous),集成中的个体学习器由不同的学习算法组成,这里的个体学习器常称为组件学习器(component learner)
集成学习方法可分为2类:
- Bagging,并行集成方法,个体学习器之间不存在强依赖关系、可同时生成的并行化方法。Bagging主要关注降低方差(variance)
- Boosting,序列集成方法,个体学习器间存在强依赖关系、必须串行生成的序列化方法。Boosting主要关注降低偏差(bias)
结合策略可分为3类:
- 平均法,应用于数值型输出
- 投票法,应用于分类型输出
- 学习法,训练数据很多的时候适用,用另一个学习器来进行结合,比如 Stacking 和 Blending
本文将主要描述 Bagging、Boosting、Stacking 和 Blending 的基本概念。
Bagging(Bootstrap AGGregatING )
Bagging 直接基于自主采样法(bootstrap sampling)。
给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过 m 次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现,由式 \(\lim\limits_{m\to \infty} (1-\frac1m)^m\to \frac1e\approx0.368\) 可知,初始训练集中约有 63.2% 的样本出现在采样集中。
Bagging 的基本流程就是采样出 T 个含有 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些学习器进行结合(平均/投票)(来源书本:机器学习)
随机森林(Random Forest)
随机森林(Random Forest,简称 RF)是 bagging 的一种扩展变体。RF 就是在以决策树为基学习器构建 bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
具体来说,传统决策树在选择划分属性时是在当前节点的属性集合(假定有 \(d\) 个属性)中选择一个最优属性;而在 RF 中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含 \(k\) 个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数控制了随机性的引入程度:若令 \(k = d\),则基决策树的构建与传统决策树相同;若令 \(k = 1\),则是随机选择一个属性用于划分;一般情况下,推荐值 \(k = \log_2d\)
(来源书本:机器学习)
随机森林的优点
- 准确率高
- 对部分特征缺失不敏感
- 训练出的模型方差小,泛化能力强
- 在训练集维度很高的情况下,仍然能够高效训练
- 训练后,可以得到变量重要性排序
- 训练可以高度并行化
随机森林的缺点
- 在某些噪声较大的训练集上容易过拟合
- 类似黑盒模型
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果
Boosting
Boosting 是指能够将弱学习器转化为强学习器的一类算法族。
机制:
先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此反复进行,直至基学习器数目达到事先制定的值T,最终将这T个基学习器进行加权结合。(来源书本:机器学习)
Boosting设计到的内容比较宽泛,有较多的实现及算法,这里只大概写一下,之后另外写一篇/几篇具体总结。
基础算法:AdaBoost(Adaptive Boosting)、GB(Gradient Boosting)
实现: GBDT(Gradient Boosting Decision Tree)、XGBoost、LightGBM
AdaBoost
AdaBoost 给每一个样本一个权值,在每一轮训练结束后,提高被前一轮弱学习器错误分类样本的权值,降低被正确分类样本的权值,使得未被正确分类的样本在下一轮中得到更多关注。
AdaBoost 组合弱学习器的时候使用加权多数表决的方法,即使分类误差率小的弱学习器在表决中起较大作用,反之起较小作用。
算法推导:(来源书本:统计学习方法)
输入:
- 训练数据集 \(T=\{(x_1,y_1),(x_2,y_2),...(x_N,y_N)\}\),其中 \(x_i\in X\subseteq R^n\),\(y\in Y = \{ -1, +1\}\)
- 弱学习算法
输出:
- 最终分类器 \(G(x)\)
步骤:
- 初始化训练数据集的权值分布 \(D_1=(w_{1,1},...,w_{1,i},...,w_{1,N}),w_{1i}=\frac 1N,i=1,2,...,N\)
- 对于 \(m=1,2,...,M\): (a)使用具有权值分布 \(D_m\) 的训练数据集学习,得到基本分类器:\(G_m(x):X→\{−1,1\}\) (b)计算 \(G_m(x)\) 在训练数据集上的分类误差率:\(e_m=\sum_{i=1}^NP(G_m(x)\not=y_i)=\sum_{i=1}^Nw_{mi}I(G_m(x_i)\not=y_i)\) (c)计算 \(G_m(x)\) 的系数:\(\alpha_m=\frac12ln(\frac{1−e_m}{e_m})\)
(d)更新训练数据集的权值分布 \[\begin{aligned} D_{m+1}=(w_{m+1,1},...,w_{m+1,i},...,w_{m+1,N})\\ w_{m+1,i}=\frac {w_{mi}}{Z_{m}}exp(−\alpha_my_iG_m(x_i)),\ i=1,2,...,N \end{aligned}\] 这里,\(Z_m\) 是规范化因子,\(Z_m=\sum_{i=1}^{N}w_{mi}exp(−\alpha_my_iG_m(x_i))\),它使 \(D_{m+1}\) 成为一个概率分布。 - 构建基本分类器的线性组合: \[f(x)=\sum_{m=1}^M\alpha_mG_m(x)\]
得到最终分类器: \[G(x)=sign(f(x))=sign(\sum_{m=1}^M\alpha_mG_m(x))\]
Gradient Boosting
Gradient Boosting在每次训练之后通过计算损失函数梯度下降的方法来获取下一轮训练时的回归树。
算法推导:(来源书本:统计学习方法)
输入:
- 训练数据集 \(T=\{(x_1,y_1),(x_2,y_2),...(x_N,y_N)\}\),其中 \(x_i\in X\subseteq R^n\),\(y\in Y = \{ -1, +1\}\)
- 损失函数 \(L(y,f(x))\)
输出:
- 回归树 \(\hat f(x)\)
步骤:
- 初始化 \(f_0(x)=\arg\min\limits_c\sum_{i=1}^NL(y_i,c)\)
- 对 \(m=1,2,...,M\): (a)对 \(i=1,2,...,N\),计算 \[r_{mi}=-[\frac{\partial L(y,f(x_i))}{\partial f(x_i)}]_{f(x)=f_{m-1}(x)}\]
(b)对 \(r_{mi}\)拟合一个回归树,得到第 \(m\) 棵树的叶结点区域 \(R_{mj},j=1,2,...,J\)
(c)对 \(j=1,2,...,J\),计算 \[c_{mj}=\arg\min\limits_c\sum_{x_i\in R_{mj}}L(y_i,f_{m-1}(x_i)+c)\]
(d)更新 \(f_m(x)=f_{m-1}(x)+\sum_{j=1}^Jc_{mj}I(x\in R_{mj})\)
- 得到回归树 \[\hat f(x)=f_M(x)=\sum_{m=1}^M\sum_{j=1}^Jc_{mj}I(x\in R_{mj}) \]
GBDT
GBDT(Gradient Boosting Decision Tree),其实就是将 GB 里的弱学习器选择为决策树,比如 CART(Classification And Regression Tree)。 GBDT 有一个严重缺陷,就是不能用类似 mini-batch 的方式来训练,这使得计算压力很大。
XGBoost(XGB)
XGBoost(eXtreme Gradient Boosting)是 Gradient Boosting 的一种高效系统实现,其针对 GBDT 框架,加入了很多改进点。
- 支持并行
- 能自动处理缺失值
- 在 cost 函数里加入了正则项
- 对 cost 函数进行了二阶泰勒展开
- 支持线性分类器
可以看看讨论[5]
LightGBM(LGBM)
LightGBM 比 XGBoost 快很多。 为了能让 GBDT 高效地用上更多的数据,我们把思路转向了分布式 GBDT, 然后就有了 LightGBM。设计的思路主要是两点,
- 单个机器在不牺牲速度的情况下,尽可能多地用上更多的数据;
- 多机并行的时候,通信的代价尽可能地低,并且在计算上可以做到线性加速。
基于这两个需求,LightGBM 选择了基于 histogram 的决策树算法。相比于另一个主流的算法 pre-sorted(如 xgboost 中的 exact 算法),histogram 在内存消耗和计算代价上都有不少优势。
Stacking
Stacking 是一种集成学习技术,通过元分类器或元回归聚合多个分类或回归模型。基础层次模型(level model)基于完整的训练集进行训练,然后元模型基于基础层次模型的输出进行训练。下面两张图能比较好的反应 Stacking 的流程。
图片来源文章[1] 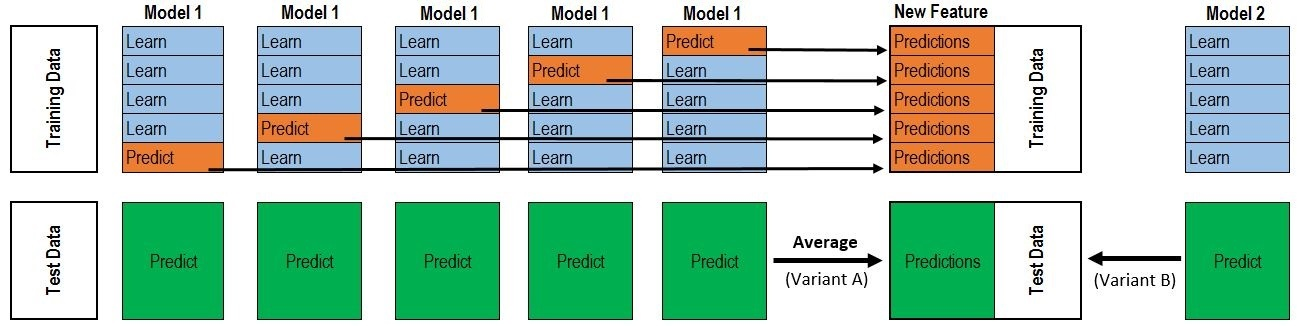
图片来源文章[2] 
使用k-fold的原因
在实现 Stacking 时,要注意的一点是,避免标签泄漏(Label Leak)。在训练次学习器时,需要上一层学习器对 Train Data 的测试结果作为特征。如果我们在 Train Data 上训练,然后在 Train Data 上预测,就会造成 Label Leak。为了避免 Label Leak,需要对每个学习器使用 K-fold,将 K 个模型对 Valid Set 的预测结果拼起来,作为下一层学习器的输入。
Stacking模型实例
条件:
- 5-flod,2 层 Stacking,4 个 Base 模型参与,分别为 M1,M2,M3,M4
- 其中,M1、M2、M3 用在第一层,M4 用在第二层
- 假设 train.csv 有 500 行,test.csv 有 300 行
步骤:
- 对 M1 进行 5-fold 交叉验证训练操作并且拼接结果获得 500x1 的训练集预测值 Train1
- 在5-fold 过程中每次都对测试集进行预测获得 300 行预测结果,最后将 5 次预测结果取平均值获得 300x1 的 Pred1
- 对 M2、M3 进行步骤 1、2 获得 Train2、Train3、Pred2、Pred3
- 现在到第二层了,使用 Train1、Train2、Train3 拼接成 500x3 的矩阵作为输入训练 M4
- 使用 M4 预测使用 Pred1、Pred2、Pred3 拼接成 300x3 的矩阵获得最终结果
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Ensemble(object):
def __init__(self, n_folds, stacker, base_models):
self.n_folds = n_folds
self.stacker = stacker
self.base_models = base_models
def fit_predict(self, X, y, T):
X = np.array(X)
y = np.array(y)
T = np.array(T)
folds = list(KFold(len(y), n_folds=self.n_folds, shuffle=True, random_state=2016))
S_train = np.zeros((X.shape[0], len(self.base_models)))
S_test = np.zeros((T.shape[0], len(self.base_models)))
for i, clf in enumerate(self.base_models):
S_test_i = np.zeros((T.shape[0], len(folds)))
for j, (train_idx, test_idx) in enumerate(folds):
X_train = X[train_idx]
y_train = y[train_idx]
X_holdout = X[test_idx]
# y_holdout = y[test_idx]
clf.fit(X_train, y_train)
y_pred = clf.predict(X_holdout)[:]
S_train[test_idx, i] = y_pred
S_test_i[:, j] = clf.predict(T)[:]
S_test[:, i] = S_test_i.mean(1)
self.stacker.fit(S_train, y)
y_pred = self.stacker.predict(S_test)[:]
return y_pred
Blending
参考[3]
blending 和 stacking 很相似,区别在于 blending 不对训练集创建 out-of-fold 预测,而是取一小部分(比如 10%)的训练集作为 holdout set,然后让基模型只在这个 holdout set 上训练。也就是每个基模型都是基于不相关的训练集数据进行训练的。
blending 的优点
- 比 stacking 简单
- 防止信息泄漏(information leak):generalizer 和 stacker 使用不同数据
- 不需要和队友分享基模型的种子,只需要把模型拿去 blending,由算法决定这个模型的去留
blending 的缺点
- 并没有充分使用所有数据
- 最终结果可能对 holdout set 过拟合
- stacking 的 CV 结果可能比使用 holdout set 的结果更加牢靠
参考资料
[1] https://zhuanlan.zhihu.com/p/26890738
[2] https://burakhimmetoglu.com/2016/12/01/stacking-models-for-improved-predictions/
[3] https://mlwave.com/kaggle-ensembling-guide/
[4] https://www.cnblogs.com/csyuan/p/6537255.html
[5] https://www.zhihu.com/question/41354392