前篇参考:学习笔记——集成学习(Ensemble Learning)
相关论文:XGBoost: A Scalable Tree Boosting System
Github:xgboost
论文总结
XGBoost 是 scalable end-to-end tree boosting system(可扩展的端到端提升树系统)
主要工作:
- 设计并构建了高度可扩展的端到端提升树系统(highly scalable end-to-end tree boosting system)
- 理论上合理的加权分位数略图法(weighted quantile sketch for efficient proposal calculation)
- 介绍了一种用于并行树学习的全新的稀疏感知算法(sparsity-aware algorithm)
- 设计了一种针对核外计算(out-of-core tree learning)的高效缓存感知数据块结构(effective cache-aware block structure)
提升树(Tree Boosting)
可以先回顾一下之前的 学习笔记——集成学习(Ensemble Learning)
输出: \[\hat y_i=\phi(x_i)=\sum\limits_{k=1}^Kf_k(x_i), \quad f_k\in\mathcal{F}\] 其中,\(\mathcal{F}=\{f(x)=w_{q(x)}\}(q:\mathbb{R}^m\to T,w\in\mathbb{R}^T)\) 是回归树空间(也叫 CART)
损失函数: \[ \mathcal{L}(\phi)=\sum\limits_il(\hat y_i, y_i)+\sum\limits_k\Omega(f_k) \\ where \quad \Omega(f)=\gamma T+\frac12\lambda||w||^2 \] 其中 \(\Omega(f)\) 就是惩罚项,相当于剪枝处理,防止过拟合,这是 GBDT 里没有的。\(T\) 为叶子结点个数,\(w\) 为叶子权重。
第 t 次迭代的时候的损失函数: \[ \mathcal{L}^{(t)}=\sum\limits_{i=1}^nl(y_i, \hat y_i^{(t-1)}+f_t(x_i))+\Omega(f_t) \\ \] 一通二阶泰勒展开的操作之后: \[ \mathcal{\tilde L}^{(t)}=\sum\limits_{j=1}^T[(\sum\limits_{i\in I_j}g_i)w_j+\frac12(\sum\limits_{i\in I_j}h_i+\lambda)w_j^2]+\gamma T \] 评价树结构 \(q\) 的评分函数: \[ \mathcal{\tilde L}^{(t)}(q)=-\frac 12\sum\limits_{j=1}^T\frac{(\sum_{i\in I_j}g_i)^2}{\sum_{i\in I_j}h_i+\lambda}+\gamma T \] 评价一个划分的式子: \[\mathcal{L}_{splite}\frac12[\frac{(\sum_{i\in I_L}g_i)^2}{\sum_{i\in I_L}h_i+\lambda}+\frac{(\sum_{i\in I_R}g_i)^2}{\sum_{i\in I_R}h_i+\lambda}-\frac{(\sum_{i\in I}g_i)^2}{\sum_{i\in I}h_i+\lambda}]-\gamma\] \(I_R\)、\(I_L\)是划分后右边和左边的节点,\(I=I_R\cup I_L\)
划分算法
树学习的一个主要问题就是找到使上面那个 \(\mathcal{L}_{splite}\) 最小的划分方式。
精确贪婪算法(Exact Greedy Algorithm)
 这个算法是要遍历所有可能的划分,找到损失最小的划分,为了有效率的实现这个算法,要先根据特征值对数据进行排序。
这个算法是要遍历所有可能的划分,找到损失最小的划分,为了有效率的实现这个算法,要先根据特征值对数据进行排序。
但是当数据不能全部加载进内存里的时候,就无法进行排序,也就没办法有效率的使用 Exact Greedy Algorithm 了,这种情况下为了高效就只能用近似算法了:
近似算法(Approximate Algorithm)
 近似算法是要先根据特征分布提出一些候选划分,然后将连续特征映射到候选节点划分出的桶里,然后选出最佳的划分。
近似算法是要先根据特征分布提出一些候选划分,然后将连续特征映射到候选节点划分出的桶里,然后选出最佳的划分。
- global 是指生成一棵树之前就进行划分选择
- local 是指每次划分前再进行划分选择
算法效果对比图 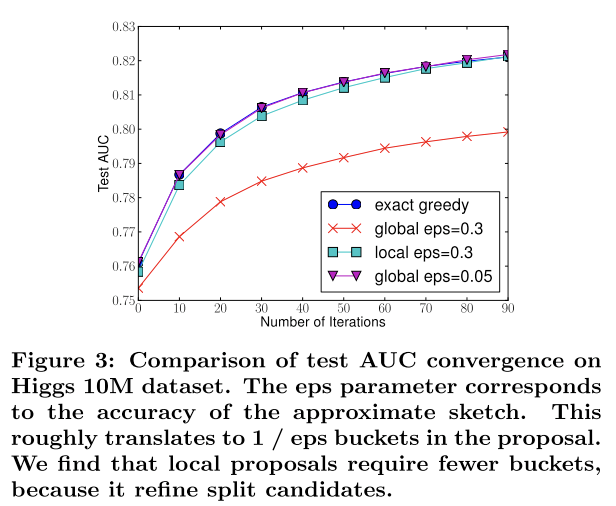
加权分位数略图法(Weighted Quantile Sketch)
提出候选划分是近似算法里重要的一步,这里选取划分的时候应该给每个样本不同的权重,以二阶偏导作为权重。对数据集 \(\mathcal{D}_k=\{(x_{1k},h_1),(x_{2k},h_2),...,(x_{nk},h_n)\}\) 定义 rank function: \[r_k(z)=\frac1{\sum_{(x,h)\in \mathcal{D}_k}h}\sum\limits_{(x,h)\in\mathcal{D}_k,x<z}h\] 表示特征值 \(k\) 比 \(z\) 小的样本比例。这个 rank function 的目的是找到候选划分 \(\{s_{k1},s_{k2},...,s_{kl}\}\) 使得: \[|r_k(s_{k,j}-r_k(s_{k,j+1}))|<\epsilon,\ s_{k1}=\min\limits_ix_{ik},\ s_{kl}=\max\limits_ix_{ik}\] 其中 \(\epsilon\) 是近似因子,也就是大概有 \(1/\epsilon\) 个候选划分。每个样本权重为\(h_i\),损失函数可以写为 \[\mathcal{\tilde L}^{(t)}=\sum\limits_{i=1}^n\frac12h_i(f_t(x_i)-g_i/h_i)^2+\Omega(f_t)+constant\]
稀疏感知算法(Sparsity-aware Split Finding)
工程应用中,有几种造成数据稀疏的情况:
- 数据缺失
- 频繁出现数值为 0 的情况
- 古老的编码方式,比如 one-hot 编码
应对稀疏矩阵中缺失值的情况,一般对每个划分定义一个默认方向,在数值缺失的情况下自动分到默认方向下。默认方向则是由稀疏感知算法自动学习出来的:  其实就是判断将缺失值样本划分到左边和划分到右边哪种增益高,取高的那种作为默认方向。这个算法可以大大提高效率。
其实就是判断将缺失值样本划分到左边和划分到右边哪种增益高,取高的那种作为默认方向。这个算法可以大大提高效率。
系统设计
针对并行学习的列数据块(Column Block for Parallel Learning)
树学习里最耗时的部分就是将数据排序,为了提高这部分的效率,文章里将数据存进 in-memory units (也叫 block)里,每个 block 里的数据以 compressed column(CSC)的格式存储,这种格式下,每个 column 以相应特征进行排序。这样的格式使输入数据只用在训练之前计算一次,然后每次迭代的时候都可以重复使用。 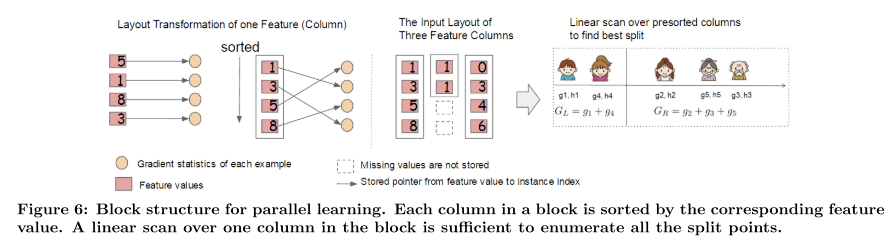 使用精确贪婪算法的时候,所有数据存在一个 block 里,使用近似算法的时候则可以存在多个 block 里,这些 block 可以分布在不同的机器上,也可以存在核外硬盘上。
使用精确贪婪算法的时候,所有数据存在一个 block 里,使用近似算法的时候则可以存在多个 block 里,这些 block 可以分布在不同的机器上,也可以存在核外硬盘上。
缓存感知访问(Cache-aware Access)
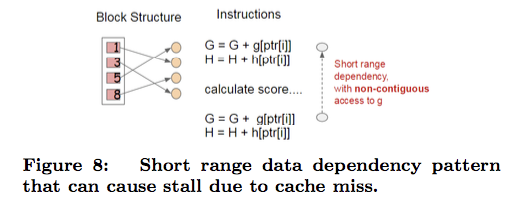 CSC 存储格式会使得数据不在连续的内存里,用普通的访问方式会使得划分查找算法效率降低,并可能导致 cache miss。
CSC 存储格式会使得数据不在连续的内存里,用普通的访问方式会使得划分查找算法效率降低,并可能导致 cache miss。
对于精确贪婪算法,使用缓存感知预取算法(cache-aware prefetching algorithm)解决问题。首先为每个线程分配一个内部 buffer,然后将 gradient statistics 存进去,使用 mini-batch 的方式来进行累计。这种预取的方式避免了直接读写内存,而是把它变成了一种长期依赖,当数据量很大的时候这种方式可以减少运行开销。
对于近似算法,选取正确的 block 大小就可以解决问题。
针对核外计算的数据块(Blocks for Out-of-core Computation)
完全利用机器资源做到可扩展学习(scalable learning)是 XGBoost 的目标。除了处理器和内存之外,利用硬盘空间来存放不能放进主内存(main memory)里的数据是很重要的一点。主要使用了两种技术来提升核外计算:
- 数据块压缩(Bock Compression) 数据块按列压缩,使用之前通过一个单独的线程解压,然后再加载进主内存里
- 数据块分片(Block Sharding)使用一种可选的方式在多个磁盘上共享数据
参数
基本参数
- booster [default=gbtree]
- gbtree:树模型
- dart:一种新型树结构,Dropouts meet Multiple Additive Regression Trees(增加 drop 树防止过拟合)
- gblinear:线性模型
- silent [default=0]
- 设置为 1 就是静默运行,0 就是正常打印运行信息
- nthread [默认设置为当前系统可获得的最大线程数]
- 运行时的线程数
- num_pbuffer [由 xgboost 自动设置,用户无需设置]
- prediction buffer 的大小,buffer 用于存储上一次 boosting 的结果
- num_feature [由 xgboost 自动设置,用户无需设置]
- 特征个数
booster 参数
gbtree 参数
- eta [default=0.3]
- 就是学习率
- range: [0,1]
- gamma [default=0]
- 进行节点进行分裂的 loss 下降的最小值,gamma 越大,算法越保守
- range: [0,∞]
- max_depth [default=6]
- 树的最大深度,用于控制树的复杂度,越深越容易过拟合
- range: [1,∞]
- min_child_weight [default=1]
- 叶子结点的最小权重和
- range: [0,∞]
- max_delta_step [default=0]
- 每棵树权重改变的最大步长,为 0 时表示不限制。这个参数一般用不上,但是在类极不平衡的逻辑回归问题上也许能派上用场
- range: [0,∞]
- subsample [default=1]
- 用于训练的子样本比例,可以避免过拟合
- range: (0,1]
- colsample_bytree [default=1]
- 构建每棵树的时候的特征采样比例
- range: (0,1]
- colsample_bylevel [default=1]
- 决定每次划分的时候使用的子样本比例
- range: (0,1]
- lambda [default=1]
- L2 正则项系数
- alpha [default=0]
- L1 正则项系数
- tree_method string [default=’auto’]
- 构建树的时候用的算法
- auto:启发式选择精确贪婪算法和近似算法里更快的那个(中小型数据集使用精确贪婪,大型使用近似)
- exact:精确贪婪算法
- approx:近似算法
- sketch_eps [default=0.03]
- 仅用于精确贪婪算法。大致转换成 O(1 / sketch_eps) 箱数,比起直接选择箱数,这样有草图准确性保证
- 通常用户不用配置这个,但是可以通过将这个值设置的更小来获得精确枚举
- range: (0, 1)
- scale_pos_weight, [default=0]
- 控制正负样本间的平衡,用于处理类不平衡问题,一种典型值:sum(负样本) / sum(正样本)
dart 参数
- sample_type [default=”uniform”]
- 采样算法的种类
- uniform:dropped 树均等的选择
- weighted:dropped 树使用权重来选择
- normalize_type [default=”tree”]
- 归一化算法的种类
- tree: 新的树的系数和每个 dropped 树的系数一致
- forest: 新的树的系数和 dropped 树的系数之和一致
- rate_drop [default=0.0]
- dropout 比例
- range: [0.0, 1.0]
- skip_drop [default=0.0]
- 跳过 dropout 的可能性。当跳过 dropout 的时候,新树以和 gbtree 一样的规则添加
- range: [0.0, 1.0]
gblinear 参数
- lambda [default=0]
- L2 正则项系数
- alpha [default=0]
- L1 正则项系数
- lambda_bias
- L2 正则项 bias,默认 0
学习任务参数
- objective [default=reg:linear]
- reg:linear 线性回归
- reg:logistic 逻辑回归
- binary:logistic 二分类问题的逻辑回归,输出概率
- binary:logitraw 二分类问题的逻辑回归,在逻辑转换之前输出 score
- count:poisson 计数数据的泊松回归,输出泊松分布的均值。柏松回归里 max_delta_step 默认设置为 0.7
- multi:softmax 使用 softmax 解决多分类问题,需要同时设置 num_class(类别数量)
- multi:softprob 和 softmax 一样,但是输出 ndata * nclass 向量,可以变形成 ndata, naclass 矩阵,结果里包含每个样本属于每个类别的概率
- rank:pairwise 使用 pairwise loss 的 ranking 任务
- reg:gamma 用于严重性数据的 gamma 回归,输出 gamma 分布的均值
- base_score [default=0.5]
- 所有实例初始化的初始化预测值,相当于全局 bias。如果迭代次数足够的话,这个值没啥影响
- eval_metric [default according to objective]
- 评价指标,不同 objective 的默认评价指标不同( rmse for regression, error for classification, mean average precision for ranking )
- rmse root mean square error
- mae mean absolute error
- logloss negative log-likelihood
- error Binary classification error rate. It is calculated as #(wrong cases)/#(all cases). For the predictions, the evaluation will regard the instances with prediction value larger than 0.5 as positive instances, and the others as negative instances.
- merror Multiclass classification error rate. It is calculated as #(wrong cases)/#(all cases).
- mlogloss Multiclass logloss
- auc Area under the curve for ranking evaluation. -ndcg Normalized Discounted Cumulative Gain ** map** Mean average precision
- ndcg@n, map@n n can be assigned as an integer to cut off the top positions in the lists for evaluation.
- ndcg-, map-, ndcg@n-, map@n- In XGBoost, NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions. training repeatively
- gamma-deviance [residual deviance for gamma regression]
- seed [default=0]
- 随机种子
命令行参数
- use_buffer [default=1]
- 是否从文本输入中创建 binary buffer
- num_round
- 迭代次数
- data
- 训练数据路径
- test:data
- 测试数据路径
- save_period [default=0]
- 保存模型的周期,设置为 10 表示 10 轮保存一次模型,设置为 0 表示不保存模型
- task [default=train] options: train, pred, eval, dump
- train 训练
- pred 预测
- eval 使用 eval[name]=filename 评估
- dump 导出模型
- model_in [default=NULL]
- 导入模型的路径
- model_out [default=NULL]
- 导出模型的路径
- model_dir [default=models]
- 训练过程中导出的模型的存放路径
- fmap
- feature map, 导出模型的时候使用
- name_dump [default=dump.txt]
- 导出的模型文件的文件名
- name_pred [default=pred.txt]
- 输出的预测文件的文件名
- pred_margin [default=0]
- 输出预测的边界,而不是转换过的概率
XGBoost 的特点
XGBoost 是 Gradient Boosting Machine 的一个 c++ 实现。XGBoost 最大的特点在于,它能够自动利用 CPU 的多线程进行并行,同时在算法上加以改进提高了精度。
XGBoost 通过如下的优化使得效率大幅提高:
- 借助 OpenMP,能自动利用单机 CPU 的多核进行并行计算
- 自定义了一个数据矩阵类 DMatrix,会在训练开始时进行一遍预处理,从而提高之后每次迭代的效率。
XGBoost 通过如下的优化提高精度:
- XGBoost 的模型和传统的 GBDT 相比加入了对于模型复杂度的控制以及后期的剪枝处理,使得学习出来的模型更加不容易过拟合
除了速度快精度高,XGBoost 还有一些很有用的进阶特性:
- 只要能够求出目标函数的梯度和 Hessian 矩阵,用户就可以自定义训练模型时的目标函数
- 允许用户在交叉验证时自定义误差衡量方法,例如回归中使用 RMSE 还是 RMSLE,分类中使用 AUC,分类错误率或是 F1-score。甚至是在希格斯子比赛中的 “奇葩” 衡量标准 AMS
- 交叉验证时可以返回模型在每一折作为预测集时的预测结果,方便构建 ensemble 模型
- 允许用户先迭代 1000 次,查看此时模型的预测效果,然后继续迭代 1000 次,最后模型等价于一次性迭代 2000 次
- 可以知道每棵树将样本分类到哪片叶子上,facebook 介绍过如何利用这个信息提高模型的表现
- 可以计算变量重要性并画出树状图
- 可以选择使用线性模型替代树模型,从而得到带 L1+L2 惩罚的线性回归或者 logistic 回归