就读过的 Memory Networks 相关论文做一个简单的汇总。
相关网络结构
- Memory Networks / Memory Neural Networks(MemNNs)
- End-to-End Memory Networks(MemN2N)
- Key-Value Memory Networks(KV-MemNNs)
- Dynamic Memory Networks(DMN)
- Imporved Dynamic Memory Networks(DMN+)
相关论文
- 《Memory Networks》[arxiv,笔记]
- 《Large-scale Simple Question Answering with Memory Networks》[arxiv,笔记]
- 《End-To-End Memory Networks》[arxiv,笔记]
- 《Key-Value Memory Networks for Directly Reading Documents》[arxiv,笔记]
- 《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》[arxiv,笔记]
- 《Dynamic Memory Networks for Visual and Textual Question Answering》[arxiv,笔记]
相关数据集
- bAbI
- bAbI-tasks(DBQA)
- WikiMovies(MovieQA)(DBQA + KBQA)
- SimpleQuestions(KBQA)
- WebQuestions(KBQA)
- WikiQA(DBQA)
相关 KB
- Freebase
- Reverb
Memory Networks
由《Memory Networks》[arxiv,笔记] 提出的一个用于解决 long-term memory 问题的框架。
基本框架
Memory Networks 基本框架包括 1 个 memory 和 4 个组件:
- I(input feature map)
把输入映射为内部特征表示(internel feature representation)\(I(x)\) - G(generalization)
使用新的输入更新旧的 memories(相当于把 I 模块的输出存入 memory):\(m_i=G(m_i,I(x),m),\forall i\) - O(output feature map)
通过新的输入和当前 memory 状态,在特征空间里产生新的输出:\(o=O(I(x),m)\) - R(response)
将特征空间输出解码为任务要求格式:\(r=R(o)\)
要注意的是,测试的时候一样会更新 memory,只是不再更新各个组件的参数。 这些组件可以使用任意现存实现方式(SVM,决策树什么的都可以)
MemNNs
MemNNs,即 memory neural networks,组件使用 NN 实现的 memory networks(这才是 MemNNs 的正式定义,之前我一直以为 memory network 就是 MemNNs……)
同样由《Memory Networks》[arxiv,笔记] 提出的一个针对文本形式输入输出的 MemNNs 实施例
基本模型
- I 模块
- 输入 text,直接原格式输出
- 在注解里提到,技术上来说,会使用 embedding 模型获得 text 对应的 embedding 向量作为输出,而不是直接输出(我觉得正文里之所以提到直接使用 original form 是为了举一个最简单的模型示例)
- 使用 embedding 向量的优缺点:在训练过程中 embedding 矩阵的参数在变,因此已经存入 memory 里的 embedding 向量会过时;但是在测试过程中,因为 embedding 矩阵的参数不会改变,所以 memory 不会过时,相比于直接存储原始文字,存入 embedding 向量使得每次使用 memory 的时候不用再进行重复的 embedding 操作,提高了效率
- G 模块
- 用于将 I 模块 的输出存入下一个可用的 memory slot 里
- \(S(x)\) 返回下一个为空的 memory slot \(N\):\(m_N=x\),\(N=N+1\)
- O 模块
- 模块找出 \(k\) 个针对输入 \(x\) 的 supporting memories 以生产输出 \(o\)
- 假设 \(k\) 最大到 2(实际生产里这个 \(k\) 会更大)
- \(k=1\),先选出得分最高的 supporting memory(最相关):\(o_1=O_1(x, m) = \mathop{\arg\max}\limits_{i=1,...,N}s_O(x,m_i)\)
- \(k=2\),根据 \(o_1\) 选出排第二的 supporting memory:\(o_2=O_2(x,m)=\mathop{\arg\max}\limits_{i=1,...,N}s_O([x,m_{o_1}],m_i)\)
- 最终输出:\(o=[x, m_{o_1},m_{o_2}]\)
- R模块
- 根据 O 模块 的输出输出文本响应:\(r=\arg\max_{w\in W}s_R([x,m_{o_1}m_{o_2}],w)\)
其中,\(s_O\) 和 \(s_R\) 都是 score 函数:\(s(x,y)=\Phi_x(x)U^\top U^\top \Phi_y(y)\)
\(U\) 是一个 \(n\times D\) 矩阵,\(D\) 是特征数量,\(n\) 是 embedding 维度。\(\Phi_x\) 和 \(\Phi_y\) 是用于将原始 text 映射到 \(D\) 维特征空间里的。
最简单的特征空间就是 bag of words(BOW),另 \(D=3|W|\),即每个词在字典里有 3 个不同的表示:1 个针对 \(\Phi_y(\cdot)\),2 个针对 \(\Phi_x(\cdot)\),依据这个输入来自 \(x\) 还是 supporting memories。\(s_R\) 和 \(S_O\) 使用不同的权重矩阵 \(U_R\)、\(U_O\)(这段还是不太懂)
训练
强监督训练,训练集里需要 inputs、responses 以及经过 labeled 的 supporting sentences,即训练过程中能够知道 \(o_1,o_2\) 的正确值。(然而这种值在 RNN、LSTM 的训练中并不好应用)
训练使用 margin ranking loss( 即要求正确答案的得分比错误答案的得分高至少一个margin \(\gamma\)),使用随机梯度下降(SGD)
给出 question \(x\),response \(r\),supporting sentences \(m_{o_1}\),\(m_{o_2}\),训练过程最小化下述式子(这公式后两行的方括号什么情况…) \[
\sum_{\bar f \not=m_{o_2}}\max(0,\gamma-s_O(x,m_{o_1})+s_O(x,\bar f))+\\
\sum_{\bar {f'}\not=m_{o_2}}\max(0,\gamma-s_O([x,m_{o_1}],m_{o_2}])+s_O([x,m_{o_1}],\bar{f'}]))+\\
\sum_{\bar r\not=r}\max(0,\gamma-s_R([x,m_{o_1},m_{o_2}],r)+s_R([x,m_{o_1},m_{o_2}],\bar r]))
\] 其中,\(r\) 是正确答案, \(\bar f\),\(\bar{f'}\) 和 \(\bar r\) 是所有的错误标签(SGD 里不是所有的,而是随机采样出来的)
- 第一行代表有没有正确挑选出得分最高的 supporting memory \(m_{o_1}\)
- 第二行代表正确挑选出了 \(m_{o_1}\) 后能不能正确找出 \(m_{o_2}\)
- 第三行代表把正确的 supporting fact 作为输入,能不能挑选出正确的答案输入 R 模块
一些扩展
- 使用词序列作为输入
添加 embedding 模型 segmenter:\(seg(c) = W_{seg}^\top U_S\Phi_{seg}(c)\) - 使用哈希的高效 memory
- Extend model to take into account when a memory slot was written to(没太看懂)
- 用语言模型处理未知词
- add the “bag of words” matching score to the learned embedding score(没太看懂)
针对 Large-scale Simple QA 的 MemNNs
由《Large-scale Simple Question Answering with Memory Networks》[arxiv,笔记] 提出的针对大规模 simple QA 的MemNNs。
这个是 MemNNs 在 KBQA 上的应用,这篇文章的模型到现在应用价值可能不是很高,但是它提出的数据集 SimpleQuestions 是现在 KBQA 问题的最大数据集了,并且只包含 Simple QA 问题(这个是优点也是缺点吧)。另外它对 KB 的预处理方式也值得参考。
基本模型
- I 模块
- 对 Freebase facts、questions、Reverb facts 进行预处理,将其转化为向量表示。
- 预处理Freebase:把 Freebase 的数据处理成适配 QA 任务的形式
- grouping:把具有相同 subject 和 relation 的 fact 聚合成一个新的 fact,应对多答案问题。例如 \((s, r, o_1)\) 和 \((s, r, o_2)\) 合成为 \((s, r, \{o_1, o_2\})\)
- 删除中间节点:把多个 fact 表示的复杂关系简化为1个 fact,这样减少推理过程,让 simple QA 可以解决更多问题。例如 \((s, r_1, o_1)\) 和 \((o_1, r_2, o_2)\) 合成为 \((s, r_2, o_2)\)
- 预处理Freebase facts:向量化三元组,使用 bag-of-symbol 表征, 得到 \(N_S\) 维(entities 和 relationships 数量之和)的向量 \(f(y)\)。\((s, r, \{o_1, o_2, ..., o_k\})\) 这类聚合三元组里每个实体的代表维度的值为 \(1/k\) 而不是 \(1\)
- 预处理questions:向量化问题,使用 bag-of-ngrams 表征,得到 \(N_V\) 维(字典大小)的向量 \(g(q)\)
- 预处理Reverb facts:向量化三元组,使用 bag-of-symbol 表征 s 和 o,使用 bag-of-words 表征 r,得到 \(N_S+N_V\) 维的向量 \(h(y)\)
- G 模块
- 用于向 memory 中添加新元素,就是将 Reverb facts 和 Freebase-based memory structure 建立连接(用于迁移学习)
- O 模块
- 根据输入,找到对应的 supporting fact
- 生成候选facts:通过问题的 n-grams of words 在 Freebase 里找到少量相关匹配实体
- Scoring:使用 embedding 模型对候选 facts 进行评分,最高得分的为 supporting fact
- question \(q\) 和 Freebase fact \(y\) 之间相似度的计算公式:\(S_{QA}(q,y)=cos(W_Vg(q),W_Sf(y))\),\(W_V\) 和 \(W_S\) 是 embedding 矩阵,维度分别为 \(d\times N_V\) 和 \(d\times N_S\)
- question \(q\) 和 Reverb fact \(y\) 之间相似度的计算公式:\(S_{RVB}(q,y)=cos(W_Vg(q),W_{VS}h(y))\),\(W_{VS}\) 也是 embedding 矩阵,维度为 \(d\times (N_V+N_S)\)
- \(d\) 是超参,embedding 矩阵 \(W_V\) 和 \(W_S\) 是要通过训练学习的参数
- R 模块
- 直接返回 output module 选择的 supporting fact 集合
MemN2N
由《End-To-End Memory Networks》[arxiv,笔记] 提出,解决了 MemNNs 存在的问题:网络每一层都需要强监督,导致训练中难以进行反向传播的计算
本文是以 DBQA 问题为例进行的。
MemN2N 和 MemNNs 的最大不同就是 O 模块 的输出 \(o\) 计算由取最大值变为了基于 Softmax 的加权平均值。
基本模型
架构图 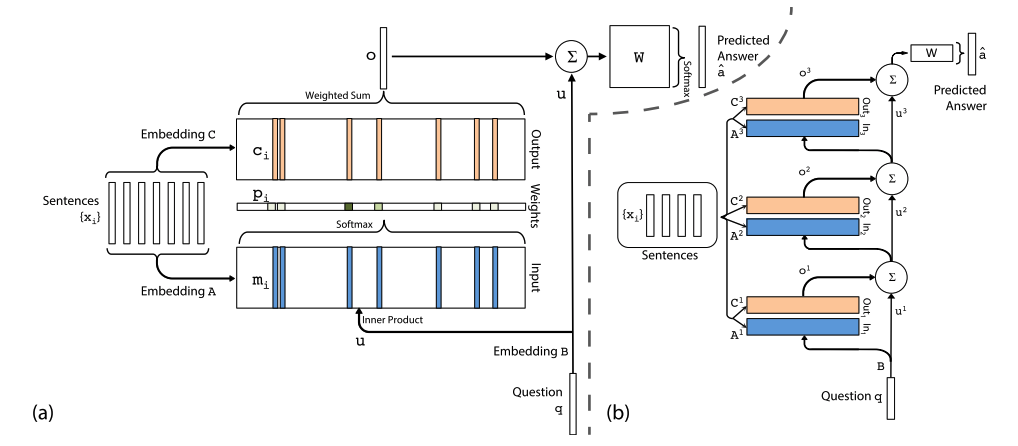 (a) 为单层模型,(b) 为多层模型
(a) 为单层模型,(b) 为多层模型
给定输入 \(x_1,...,x_n\),查询(query)\(q\),模型输出回答 \(a\)
单层模型
参考上图 (a),模型里有两个 memory 块,一个 input 用于计算每个 memory 的概率 \(p_i\),一个 output 用于根据 \(p_i\) 求加权和 \(o\) ,这个思路就是 soft attention 嘛
- I 模块 & G 模块(Input memory representation)
- 给定输入 \(\{x_i\}\),首先将其 embed 为 \(d\) 维的 memory 向量 \(\{m_i\}\)(由 embedding 矩阵 \(A\) 获得),并存入 memory
- 给定的查询 \(q\) 也 embed 为 \(d\) 维获得内部状态(internal state)\(u\)(由 embedding 矩阵 \(B\) 获得)
- 在 embedding 空间里计算 \(u\) 和 \(m_i\) 的相似度(使用softmax计算内积):\(p_i=Softmax(u^Tm_i)\)(其实这一步应该算到 O 模块 里)
- O 模块(Output memory representation)
- 每个 \(x_i\) 有一个相关输出向量 \(c_i\)(由 embedding 矩阵 \(C\) 获得)
- response 向量 \(o = \sum\limits_ip_ic_i\)
- R 模块(Generating the final prediction)
- 预测标签 \(\hat a=Softmax(W(o+u))\),\(W\) 为训练参数
多层模型
参考上图 (b),多层模型就是单层模型的堆叠。
每一层都有各自的 2 个 memory 块,输入 \({x_i}\) 相同,不过每层的 embedding 矩阵 \(A\)、\(C\) 是独立的;单层模型通过 \(u\) 集联,每层输入的 \(u\) 都通过上一层的 \(u\) 及输出 \(o\) 相加获得。
具体第 \(k\) 层:
- 当前层的 \(m_i\),\(c_i\) 都由 embedding 矩阵 \(A^k\),\(C^k\) 获得
- 下一层的输入 \(u^{k+1}=u^k+o^k\)
- 网络最终输出 \(\hat a=Softmax(Wu^{K+1})=Softmax(W(o^K+u^K))\)
两种权重取值方法:
- Adjacent
- 每一层的输出 embedding 矩阵是下一层的输入 embedding 矩阵(\(A^{k+1}=C^k\))
- 预测矩阵和输出 embedding 矩阵相同(\(W^T=C^K\))
- question 的 embedding 矩阵和第一层的输入 embedding 矩阵相同(\(B=A^1\))
- Layer-wise(RNN-like)
- 输入输出 embedding 矩阵每层均相同(\(A^1=A^2=...=A^K, C^1=C^2=...=C^K\))
- 应用线性映射 \(H\) 获得 \(u^{k+1}\):\(u^{k+1} = Hu^k+o^k\)
- 这种取值方法下的 MemN2N 和传统 RNN 类似,就是把 RNN 的输出划分为了 internal 和 external 部分(internal 部分考虑 memory,external 部分考虑预测标签), \(u\) 为隐藏状态,\(p\) 为 internal 输出。明确规定了在 \(K\) 跳过程中保存 outputs 到 memory 里(soft),而不是像 RNN 那样对它们进行采样(sampling)。
- RNN: \[\begin{align*} &o^k = Vu^k + c \\ &u^{k+1} = tanh(Ux^k + Wu^{k} + b) \\ \end{align*}\]
- MemN2N: \[\begin{align*} &p^k=Softmax((u^k)^Tm^k) \\ &u^{k+1}=Hu^k+Cp^k\\ \end{align*}\]
KV-MemNNs
由 《Key-Value Memory Networks for Directly Reading Documents》[arxiv,笔记] 提出,基于 MemN2N 的架构,将其 memory 存储的形式变为向量对 \((k_1,v_1),...,(k_M,v_M)\)
本文提出了直接使用文档数据替代 KB,解决 KBQA 问题。另外为了验证 KV-MemNNs 在文档和 KB 上的效果,构造了数据集 WikiMovies。
基本模型
架构图 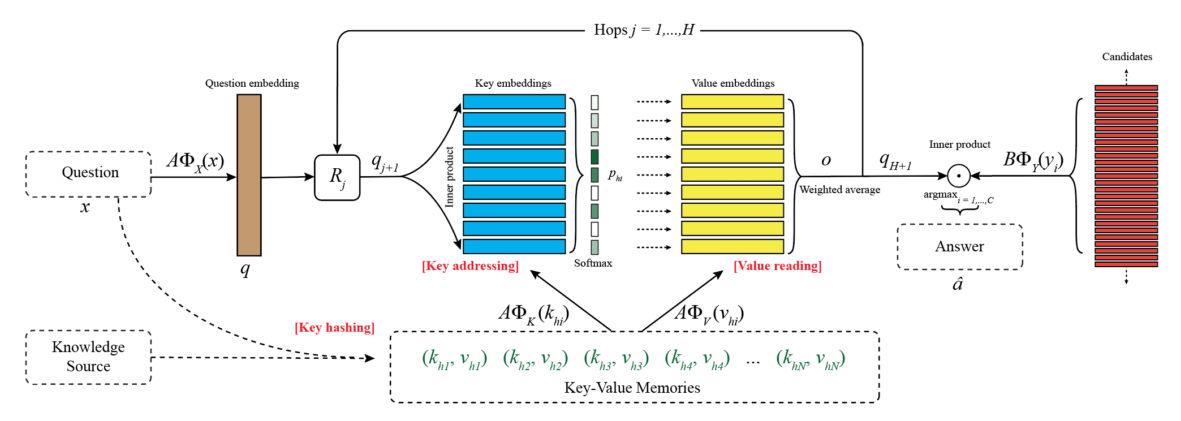
模块 O 针对 memory 形式的改变进行了修改
- Key Hashing:根据问题 \(x\) 预先选择出 N 个memory 对 \((k_{h_1},v_{h_1}),...,(k_{h_N},v_{h_N})\),要求这些 key 至少有一个词和问题里的相同(要求是词频小于 1000 的词,为了排除停用词)
- Key Addressing:通过比较问题和每个 key 计算 memory 对和问题的相关可能性(relevance probability):\(p_{h_i}=Softmax(A\Phi_X(x)\cdot A\Phi_K(k_{h_i}))\),其中,\(\Phi\) 是维度为 D 的 feature maps,\(A\) 是 \(d\times D\) 矩阵
- Value Reading:使用加权和读取 value,返回 \(o=\sum\limits_ip_{h_i}A\Phi_V(v_{h_i})\)
上面的步骤重复进行 H hops
- controller 神经网络使用 \(q=A\Phi_X(x)\) 作为 query
- 在得到 hop 1 的 \(o\) 后,hop 2 的 query 更新为 \(q_2=R_1(q+o)\),\(R\) 是 \(d\times d\) 矩阵。
- hop \(j\) 有 \(R_j\),\(q_{j+1}=R_j(q+o)\),\(p_{h_i}=Softmax(q_{j+1}^\top A\Phi_K(k_{h_i}))\)
- 在 H hop 之后,输出预测结果 \(\hat a=\arg\max_{i=1,...,C}Softmax(q_{H+1}^\top B\Phi_Y(y_i))\),\(y_i\) 是可能的候选输出
矩阵 \(A\),\(B\),\(R_1,...,R_H\) 是训练中需要学习的参数
Key-Value 实现方式
- KB Triple
KB,针对 triples(subject, relation, object),key 是 subject 和 relation,value 是 object。然后需要将 subject 和 object 交换,relation 取反再存一次(KB 大小翻倍) - Sentence Level
document,每个 memory slot 编码一个句子的情况,key 和 value 都是用 bag-of-words 的形式编码的整个句子(和标准 MemNN 里一样) - Window Level
document,分割成 W 个词的窗口(中心词是实体),key 是用 bag-of-words 编码后的整个窗口,value 是中心词 - Window + Center Encoding
document,和 Window Level 的区别就是使用不同 feature 对中心词和窗口中除了中心词以外的词进行编码 - Window + Title
document,key 还是上面两条提到的窗口,value 是 document 的 title,另外也保留 Window Level 里的所有 memory 对
DMN
由《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》[arxiv,笔记] 提出,这篇文章不是 facebook 的。
本文里提出大部分 NLP 问题都可以转换为 QA 问题,DMN 则是针对 QA 任务设计,因此可以用于几乎所有自然语言任务。
DMN 正式的提出来 Memory Networks 和 Attention 机制的结合使用,前面 MemN2N 之类的都只能说是用到了和 soft attention 类似思路的加权平均值,文章里好像没有正式提到 Attention
DMN 的结构不是 MemNNs 的 I、G、O、R 模块 了。
QA 问题的核心:input-question-answer
模型
DMN 架构图 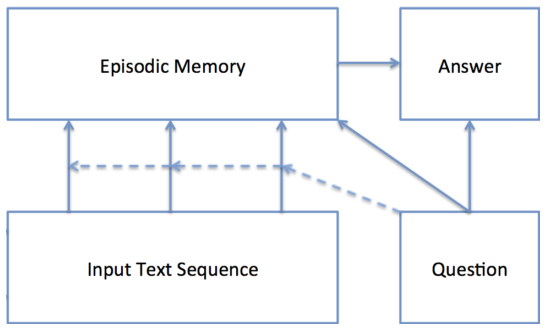
- Input Module:编码原始文本数据 input,将其转换成向量表示
- Question Module:编码原始文本数据 question,将其转换成向量表示
- Episodic Memory Module:事件记忆模块,通过 attention 机制选择需要注意的 input 并根据 question 给出 memory 向量。这个模块有 retrieve 新信息的能力
- Answer Module:根据最终的 memory 向量生成答案
架构示例 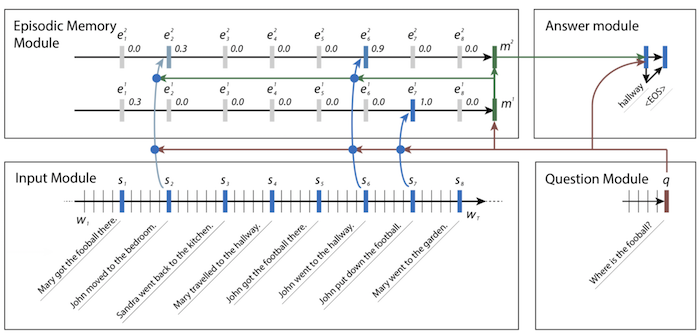
Input module
使用 RNN 对 input 序列进行编码。本文里使用的 GRU
- 模块输入是具有 \(T_I\) 个词 \(w_1,...,w_{T_I}\) 的序列
- 每个 step \(t\) 里,网络更新隐藏状态 \(h_t=RNN(L[w_t],h_{t-1})\),\(L\) 是 embedding 矩阵。
- 模块的输出是 RNN 的隐藏状态。当输入是句子列表的时候,把数据连接成一个单词的长列表,每个句子结尾加一个 end-of-sentence token。每个 end-of-sentence token 处的隐藏状态就是模块的最终表征。(具体架构示例图)
Question Module
使用 RNN 对 question 进行编码。
- 模块输入是具有 \(T_Q\) 个词的 question
- 隐藏状态 \(q_t=GRU(L[w_t^Q],q_{t-1})\),Input module 和 question module 共享同一个 embedding 矩阵 \(L\)
- 输出是最终的隐藏状态 \(q=q_{T_Q}\)
Episodic Memory Module
- 事件记忆模块根据 input module 的输出进行迭代,更新模块内部的事件记忆
- 每次迭代中,attention 机制根据 fact 表征 \(c\),question 表征 \(q\) 和前一个 memory \(m^{i-1}\) 来生成事件 \(e^i\)
- 然后事件和前一个 memory 都用来更新当前 memory:\(m^i=GRU(e^i,m^{i-1})\),GRU 初始化 \(m^0=q\)
\(T_M\) 之后,模块最终输出 \(m^{T_M}\) 到 answer module
- Need for Multiple Episodes
- 每次迭代关注不同的输入
- 例如架构示例里第一次关注 football,第二次关注 John
- Attention Mechanism
- gating function:\(g_t^i=G(c_t,m^{i-1},q)\),\(c_t\) 为候选 fact,\(G\) 是 scoring function
- 特征向量 \(z(c,m,q)=[c,m,q,c\cdot q,c\cdot m,|c-q|,|c-m|,c^TW^{(b)}q,c^TW^{(b)}m]\)
- scoring function \(G(c,m,q)=\sigma(W^{(2)}\tanh(W^{(1)}z(c,m,q)+b^{(1)})+b^{(2)})\)
- Memory Update
- 隐藏状态 \(h_t^i=g_t^iGRU(c_t,h_{t-1}^i)+(1-g_t^i)h_{t-1}^i\)
- 事件 \(e^i=h_{T_C}^i\)
- Criteria for Stopping
- 如果 gate function 选择到输入中一个特殊的 end-of-passes 表征,则停止迭代
Answer Module
根据任务类型不同,模块可能是最后输出一个 answer,也可能每个 time step 都输出
- 初始化 last memory \(a_0=m^{T_M}\),每个 time step,输入 question \(q\),最后一个隐藏状态 \(a_{t-1}\)
- \(a_t=GRU([y_{t-1},q],a_{t-1})\)
- 模块输出 \(y_t=softmax(W^{(a)}a_t)\)
DMN+
由《Dynamic Memory Networks for Visual and Textual Question Answering》[arxiv,笔记] 提出,作为 DMN 的改进,改进了 DMN 在以下两种情况下的表现:
- 训练时无 supporting facts
- 使用诸如图片等其他形式的数据(非文本数据)
模型
DMN+ 相比于 DMN 修改的两部分:
- input representation
- attention 机制与 memory 更新
针对 Text QA 的 input module
在没有 supporting facts 的情况下 DMN 表现不好的原因:
- GRU 只能让句子从上文中获得信息,而不能从下文中获得
- 可能一些 supporting 句子相距太远了,对于 word level GRU 无法获得它们间的关联
模块示例图 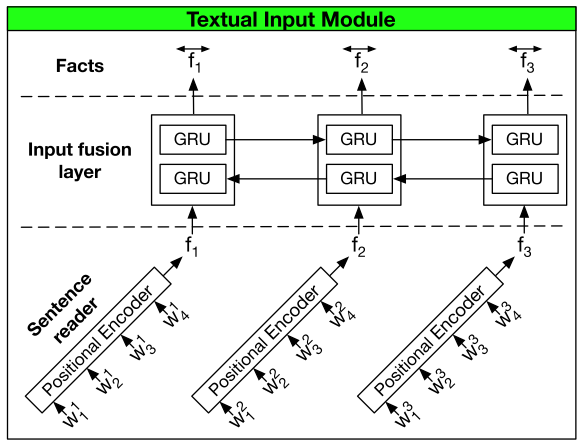
DMN+ 将 DMN 的 input module 由单向 GRU 换成两个组件,Sentence reader 和 Input fusion layer
- Sentence reader
- 负责将输入的词编码为 sentence embedding
- 输入 word tokens \([w_1^i,...,w_{M_i}^i]\),输出 sentence encoding \(f_i\),其中 \(M_i\) 是句子的长度
- 可以使用任意的编码方式,上图里用的 Positional Encoder,用 GRU 或者 LSTM 也可以
- Positional Encoder:
- \(f_i=\sum_M^{j=1}l_j\cdot w_j^i\)
- \(l_{jd}=(1-j/m)-(d/D)(1-2j/M)\)
- 其中,\(d\) 为 embedding index,\(D\) 是 embedding 维度
- Input fusion layer
- 负责获得句子间的关联
- 将 DMN 的单向 GRU 换成双向 GRU(bi-directional GRU)
- Bi-GRU:
- \(\overrightarrow{f_i}=GRU_{fwd}(f_i,\overrightarrow{f_{i-1}})\)
- \(\overleftarrow{f_i}=GRU_{bwd}(f_i,\overleftarrow{f_{i+1}})\)
- \(\overleftrightarrow{f_i}=\overrightarrow{f_i}+\overleftarrow{f_i}\)
针对 VQA 的 input module
模块示例图 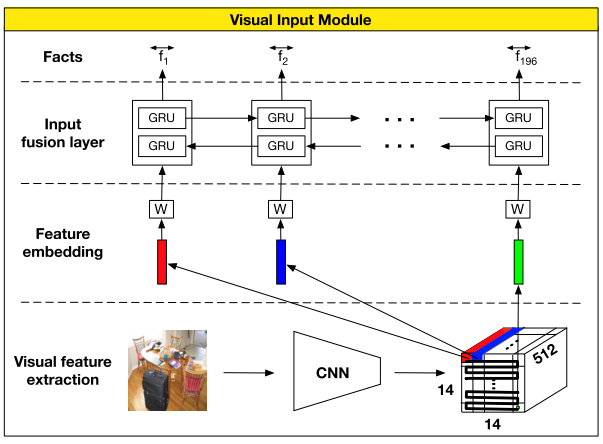
DMN+ 针对 VQA 的 input module 分为 3 个 组件
- Local region feature extraction
- 使用基于 VGG-19 的 CNN
- 首先把输入 rescale 到 448x448,最后的池化层输出维度 \(d=512\times 14\times 14\),也就相当于 196 个 维度为 512 的 local regional 向量
- Visual feature embedding
- 使用 tanh 激活函数的 linear layer
- 用于将 local regional 向量投射到 question 向量使用的文字特征空间
- Input fusion layer
- 和针对 Text QA 的 input module 里的 Input fusion layer 一样
事件记忆模块
模块示例图 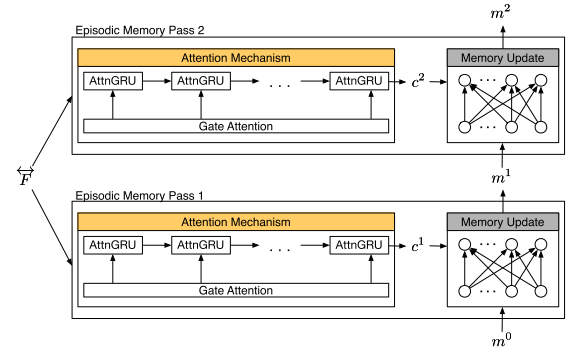
attention gate \(g_i^t\) 的计算如下
\[\begin{align*} &z_i^t=[\overleftrightarrow{f_i}\circ q;\overleftrightarrow{f_i}\circ m^{t-1};|\overleftrightarrow{f_i}-q|;|\overleftrightarrow{f_i}-m^{t-1}|] \\&&&&\\ &Z_i^t=W^{(2)}\tanh (W^{(1)}z_i^t+b^{(1)})+b^{(2)} \\&&&&\\ &g_i^t=Softmax(Z^t)=\frac{\exp(Z_i^t)}{\sum_{k=1}^{M_i}\exp(Z_k^t)} \end{align*}\]
其中, \(\overleftrightarrow{f_i}\) 是第 \(i\) 个 fact,\(m^{t-1}\) 是前一个 memory,\(q\) 是原始问题,\(\circ\) 是 element-wise product,\(|\cdot|\) 是 element-wise 绝对值
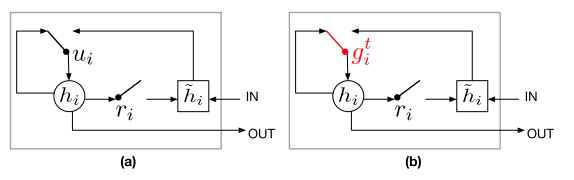 (a) 为传统 GRU 模块,(b) 为基于 attention 的 GRU 模块
(a) 为传统 GRU 模块,(b) 为基于 attention 的 GRU 模块
事件记忆模块主要分为两部分:Attention Mechanism 和 Episode Memory Update
- Attention 机制有两种选择
- Soft Attention
- 直接求加权和,contextual 向量 \(c^t=\sum_{i=1}^Ng_i^t\overleftrightarrow{f_i}\)
- 两个优点:便于计算;如果 softmax 激活是 spiky 的,它可以通过仅选择一个 fact 作为 contextual 向量来保持可微分,接近于 hard attention 函数(?)
- 缺点:求和过程丢失了位置和排序的信息
- 基于 Attention 的 GRU
- 参考上图,把 GRU 单元里的 \(u_i\) 换成了 \(g_i^t\)
- \(h_i=g_i^t\circ\tilde h_i+(1-g_i^t)\circ h_{i-1}\)
- \(g_i^t\) 是一个使用 Softmax 计算的标量,而 \(u_i\) 是一个使用 Sigmoid 计算的 \(n_H\) 维向量
- Soft Attention
- Episode Memory 更新
- 不再像 DMN 里一样用 GRU,而是用了 ReLU layer 来更新 memory
- \(m^t=ReLU(W^t[m^{t-1};c^t;q]+b)\)
总结
- 重新读了一遍论文,修改了不少原始笔记里的理解错误,希望每读一遍都能理解的更深入一点