算是第 1 次参加 kaggle 比赛,也是第一次参加 NLP 方向的比赛,虽然最后只拿到了前 7% 的成绩,但是收获还是很多的。
比赛简介
Toxic Comment Classification Challenge
这个比赛要求建立一个多分类器,检测不同类型的负面评论
负面评论分为 6 类:
- toxic
- severe_toxic
- obscene
- threat
- insult
- identity_hate
这个比赛的数据集来自维基百科的评论页面。
评估标准是 6 类的 ROC-AUC 的平均值。
比赛中途才将评估标准换成 ROC-AUC,本来是 Log Loss
数据分析(EDA)
由于开始做比赛的时候已经比较晚了,讨论串里已经有比较好的 EDA 了。
训练数据长这样
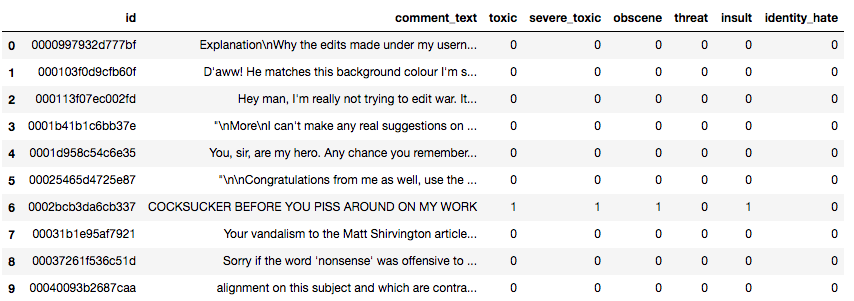
讨论[1]里对数据的分布之类的基本信息做了分析,有几个比较重要的信息:
类不平衡(class imbalance)问题,训练数据总数为 159571,非负面评论数量为 143346,6 类标签为 1 的总数量为 35098
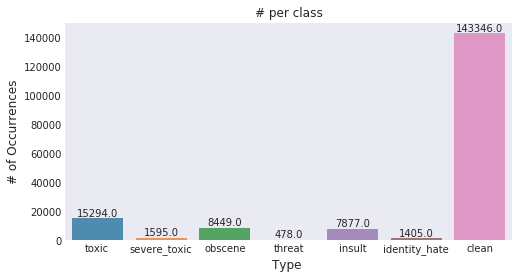
这是一个 Multi-tagging 问题
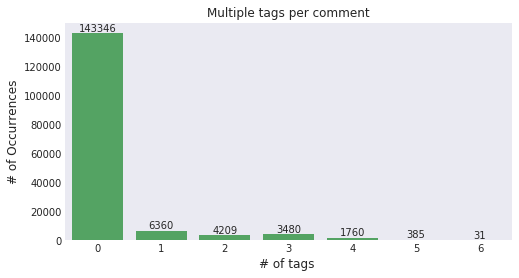
数据预处理
数据增广
讨论[3]里提供的方法,获奖方案都用了这个方法进行数据增广,可惜我比赛期间没有看到。 方法很简单,就是用基于 Google Translate API 的 TextBlob 库将评论翻译成其他语言(德语/法语/西班牙语之类的),再翻译回英语,获得成倍的训练数据。
另外还有讨论[4]里的方法,用基于马尔可夫链的 markovify 库生成句子。这个方法可以针对某个 tag(比如 threat)生成句子。不过讨论作者说这个方法并不能提高 LB 成绩。我猜测是用这个方法生成的句子只增加了数据量而没有增加信息量吧。
词汇纠错
使用库对拼写错误的单词进行纠错,这类的库有挺多种的。例如 TextBlob。讨论串里也有参赛选手自己写的,参考讨论[5]
词纠正
需要纠正的词有挺多种类的,例如下面
- 把数字 0~9 替换成对应的英文
- 把一些缩写替换成对应的全拼
- 把一些特殊的变体替换成本来的文字
模型
LSTM 与 GRU 互换只需要把 LSTM/GRU 那一层互换就行了。
embedding 矩阵的话 Word2Vec、fastText 和 GloVe 预训练出来的那几个都试了,最后选的 fastText 预训练的 crawl-300d-2M 和 GloVe 预训练的 GloVe.840B.300d 结合使用。
Bi-GRU + Conv + Pooling
参考讨论[8]
1 | def get_model(): |
这个模型也是我最后主要使用的,具体可以见论文《Recurrent Convolutional Neural Networks for Text Classification》(笔记)以及 Blog
Capsule + Bi-GRU
参考讨论[9],Capsule 的 keras 实现也在链接里。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def get_model():
inp = Input(shape=(maxlen,))
x = Embedding(max_features,embed_size,input_length=maxlen,
weights=[embedding_matrix],trainable=False)(inp)
x = SpatialDropout1D(0.28)(x)
x = Bidirectional(GRU(128, activation='relu', dropout=0.25,
recurrent_dropout=0.25, return_sequences=True))(x)
capsule = Capsule(num_capsule=10, dim_capsule=16, routings=5,
share_weights=True)(x)
capsule = Flatten()(capsule)
capsule = Dropout(0.25)(capsule)
output = Dense(6, activation='sigmoid')(capsule)
model = Model(inputs=input1, outputs=output)
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
return model
Attention + LSTM
参考讨论[10] 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def get_model():
embedding_layer = Embedding(nb_words,MBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=False)
lstm_layer = LSTM(num_lstm, dropout=0.25, recurrent_dropout=0.25,
return_sequences=True)
inp = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
x = embedding_layer(inp)
x = lstm_layer(x)
x = Dropout(0.25)(x)
merged = Attention(MAX_SEQUENCE_LENGTH)(x)
merged = Dense(256, activation='relu')(merged)
merged = Dropout(0.25)(merged)
merged = BatchNormalization()(merged)
preds = Dense(6, activation='sigmoid')(merged)
model = Model(inputs=[inp], outputs=preds)
model.compile(loss='binary_crossentropy', optimizer='rmsprop',
metrics=['accuracy'])
return model
获奖方案分析
1st方案
参考讨论[6]
1. Diverse pre-trained embeddings(baseline public LB of 0.9877)
尝试不同的词嵌入矩阵
2. Translations as train/test-time augmentation (TTA) (boosted LB from 0.9877 to 0.9880)
(这个方法3.1的数据增广里有提到)这个简单的TTA让模型提升了极大的效果,比如:
- Vanilla Bi-GRU model: 0.9862LB
- (w/ train-time augments): 0.9867 LB
- (w/ test-time augments): 0.9865 LB
- (w/ both train/test-time augments): 0.9874 LB
3. Rough-bore pseudo-labelling (PL) (boosted LB from 0.9880 to 0.9885)
伪标签,半监督学习方案。这个方法就是将强学习器预测出的测试集结果加入训练集中训练,这个方法一般可以使强学习器的效果获得提升。通过这个方法可以改善训练集和测试集分布不一样的情况。 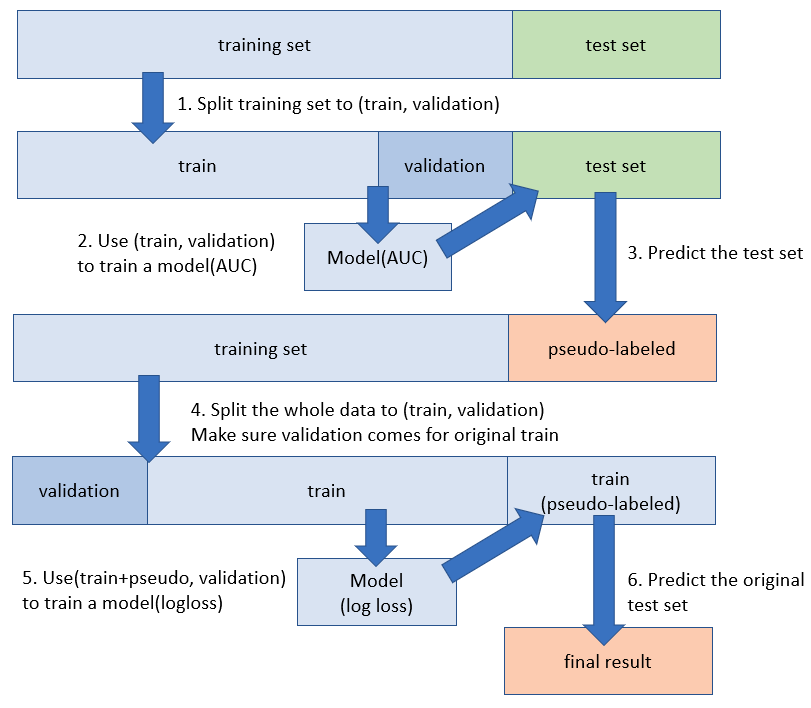
4. Robust CV + stacking framework (boosted LB from 0.9885 to 0.9890)
使用了LightGBM作为stacker,使用准确率(accuracy)、对数损失(log loss)和AUC作为CV标准
此外,还提到了研究过程中的几个发现:
- 对模型结构的小改变对最终结果影响很小(增加dropout层、attention机制之类的)
- preprossing对结果的影响也很小
- 许多评论最后一句才决定它是负面评论的,所以这个方案的一些模型里专门额外加入评论的最后25~50词进行训练
- 评论里词的顺序很关键,顺序不同可能意思截然相反,所以CNN效果普遍没有RNN效果好
- RNN是效果最好的,其他模型几乎都到不了RNN的效果,唯一能到的是Attention Is All You Need,但是训练耗时很长
- Tensorflow在很多方面都优于Keras,比如实现Attention Is All You Need或者一些扩展。不过Keras在快速迭代速度上很有优势
- 用不同oof splits混合模型回导致CV过拟合,但不会使Public LB相较于Private LB过拟合
2nd和3rd的解决方案也差不多,获奖的重点就在于TTA的使用、好的CV、大量的训练、合适的Stacking。
优秀的Single Model
参考讨论[7]
基于RNN的一个标准模型,Keras实现。
架构
- 第一层: 集联使用fastText和GloVe词嵌入矩阵。Glove里没有的词就用fastText,但是反之不然。最后还是没有对应词向量的词就用’something’的词向量替代。另外还额外添加了一个值,如果所有字母都大写就把值设置为1,反之为0。
- 第二层: SpatialDropout1D(0.5)
- 第三层: Bidirectional CuDNN LSTM with a kernel size 40。作者发现LSTM作为第一层比GRU的效果要好
- 第四层: Bidirectional CuDNN GRU with a kernel size 40.
- 第五层: 最终状态、max pooling、average pooling和两个特征“特殊单词率”、“全为大写”的级联。
- 第六层: 输出层
超参数和Preprocessing
- Batch size: 512. I found that bigger batch size makes results more stable.
- Epochs: 15.
- Sequence length: 900.
- Optimizer: Adam with clipped gradient.
- Preprocessing: Unidecode library to convert text to ASCII first and after that filtering everything except letters and some punctuation.
Reference
- Stop the S@#$ - Toxic Comments EDA | Kaggle
- Feature engineering | Kaggle
- A simple technique for extending dataset
- Extending Train Data with Markov Chains - AUC
- Spell Checker using Word2vec
- 1st place solution overview
- About my 0.9872 single model
- Bi-GRU-CNN-Poolings
- Capsule net with GRU
- keras lstm attention glove840b,lb 0.043
最后存了一张特别喜欢的图,出处是 Rick and Morty 里递黄油的机器人 